
Когда говорят о мониторинге Kubernetes, обычно имеют в виду три вещи: метрики, графики и алерты. Это базис. Но даже при наличии всех трёх система может не работать так, как хотелось бы, — и дело здесь не в инструментах.
Мы разрабатываем Deckhouse Kubernetes Platform (DKP) уже более восьми лет. За это время под управлением платформы оказалось более 1000 кластеров у 260+ клиентов — от стартапов до компаний из нефтегазовой и банковской сфер. Этот опыт позволил нам понять: мониторинг должен проектироваться вокруг людей, которые им пользуются. Именно так устроена система наблюдаемости в DKP.
Проблема, о которой редко говорят
Стандартный Prometheus может потреблять до 10–15 % ресурсов всего кластера. Это ощутимо. Несколько лет назад мы задались вопросом: можно ли сделать мониторинг, который почти ничего не стоит?
Результатом двух лет работы стал Deckhouse Prom++ — форк ванильного Prometheus с полной совместимостью по API, но с потреблением ресурсов в 10 раз меньше. Сегодня Prom++ — основа системы мониторинга в DKP. Мы сделали его Open Source под лицензией Apache 2, и он уже завоевал признание среди пользователей Prometheus и VictoriaMetrics. Подробнее о Deckhouse Prom++ рассказали в этой статье.
Но даже «дешёвый» по ресурсам мониторинг не решает главного вопроса: для кого и для чего он работает? Чтобы найти ответ, разберём ключевые подходы к организации системы наблюдаемости.
Концепции организации наблюдаемости
Два типа пользователей платформы
Возьмём типичный Kubernetes-кластер. В нём есть служебные неймспейсы с компонентами платформы — Ingress Nginx, Kubernetes API, сам мониторинг — и неймспейсы с приложениями команды разработки.
Эти команды смотрят на мониторинг с разных позиций.
Оператора платформы интересует: работает ли Ingress, сколько ресурсов он потребляет, нет ли ошибок в системных компонентах. Его фокус — стабильность инфраструктуры.
Разработчика приложений интересует совсем другое: коды ответов его сервиса, задержки, количество запросов. Ему важна производительность конкретного приложения.
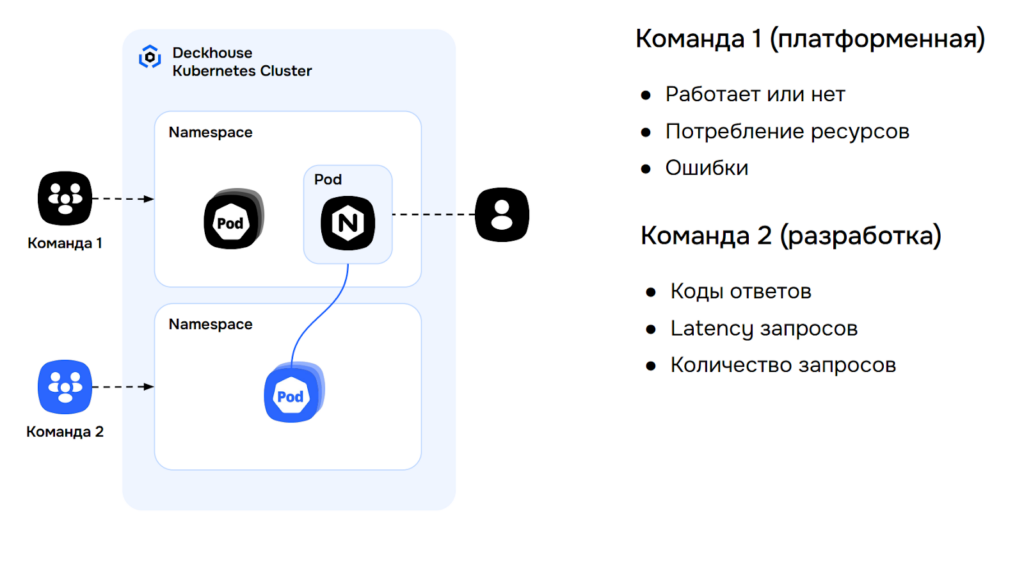
Пытаться создать один дашборд для всех — значит обречь обе команды на постоянный информационный шум. Универсальный дашборд никому не удобен: оператор видит лишнее, разработчик не находит нужного.
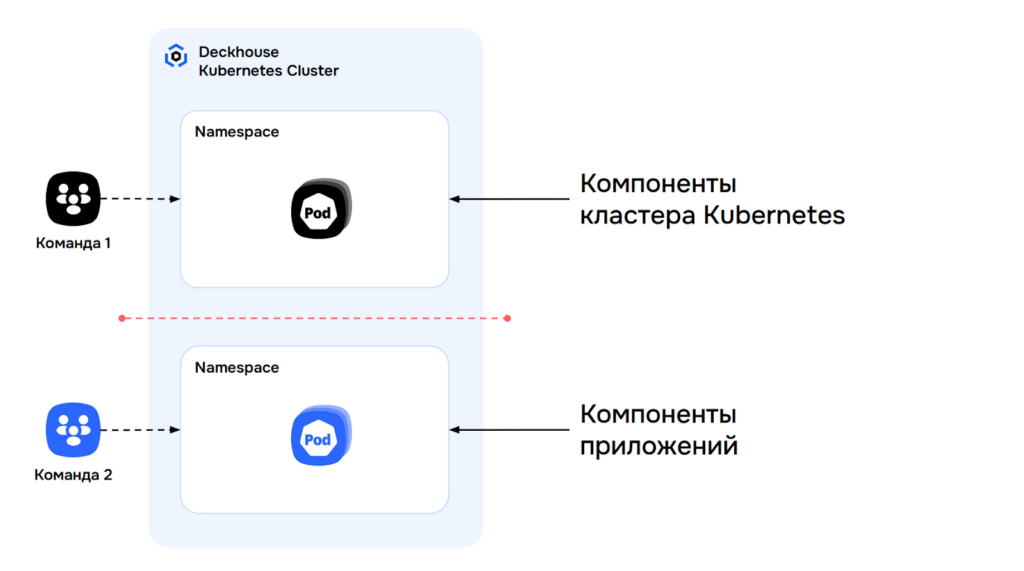
При этом есть информация, которая нужна всем: запросы к Ingress, общее потребление ресурсов подами и контроллерами. Её нужно показывать отдельно, без дублирования. В результате появляются универсальные дашборды и алерты, которые нужны всем.
Drill-down: от симптома к причине
Представьте: у команды разработки десятки микросервисов в разных неймспейсах. Пользователи начинают получать 500-е ошибки. С ходу непонятно, что именно сломалось.
В такой ситуации выручает подход drill-down. Сначала — верхнеуровневый дашборд по всем неймспейсам. Нашли проблемный? Перешли в него. Дальше — к конкретному контроллеру, затем к поду.
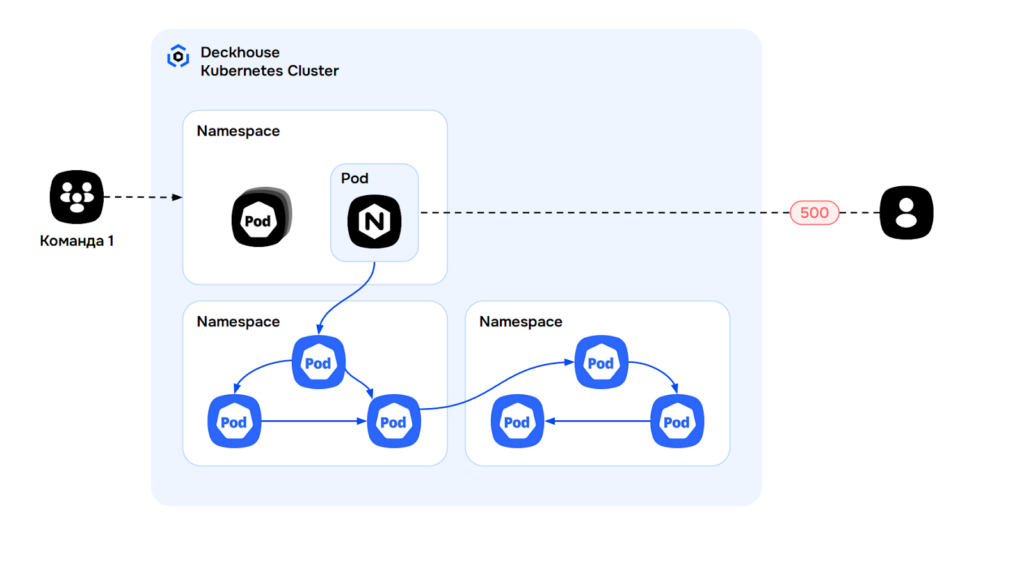
Путь от симптома до корневой причины проходится по цепочке связанных дашбордов, а не через один перегруженный экран.
Мультитенантность: каждая команда в своём пространстве
В стандартной схеме все метрики и дашборды лежат в общем пространстве. Это быстро создаёт проблемы: конфликты имён, вопросы безопасности, сложности с разграничением доступа.
Удобнее, когда каждая команда управляет своими алертами, дашбордами и каналами уведомлений в рамках своего неймспейса.
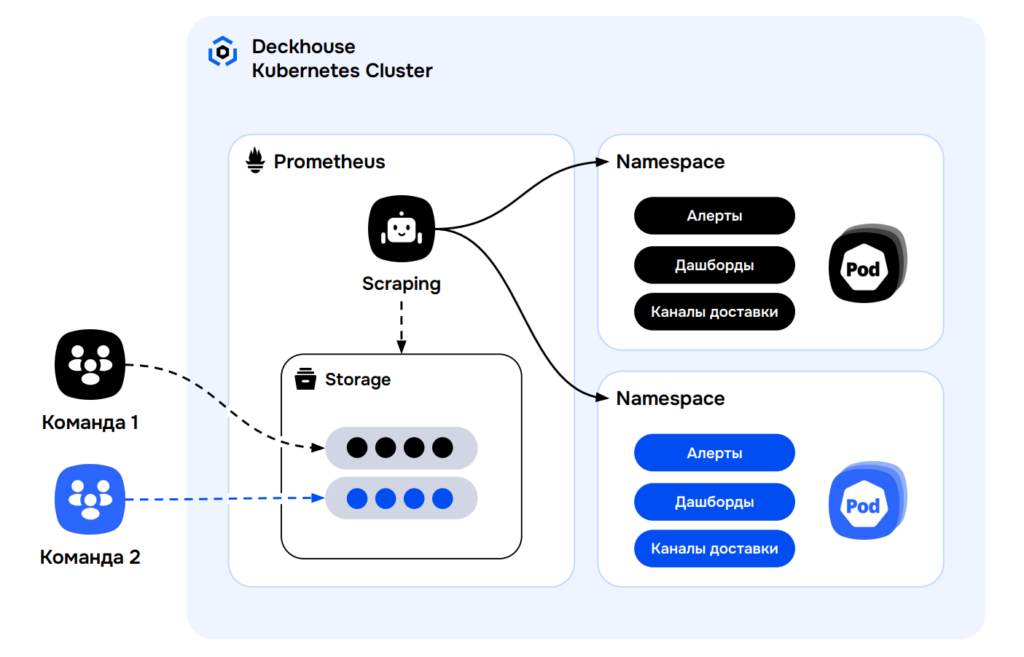
В идеале — через GitOps: сервис деплоится из Git, и вместе с ним в кластер «приезжают» его алерты и дашборды, полностью изолированные от остальных команд.
Как устроена наблюдаемость в Deckhouse Kubernetes Platform
Мониторинг в DKP проектировался как часть платформы, а не как отдельный набор инструментов. Он учитывает роли пользователей, зоны ответственности и требования к изоляции.
Единый интерфейс с разграничением по ролям
У DKP есть единый веб-интерфейс для управления кластером и мониторингом — без переключения между разными UI. Интерфейс адаптирован под роли: операторы платформы и команды разработки видят разные разделы, дашборды и точки входа в мониторинг.
Три типа дашбордов и алертов
Мы реализовали чёткую иерархию:
- ClusterObservabilityDashboards — для операторов платформы. Живут на уровне кластера, показывают состояние его компонентов.
- ObservabilityDashboards — для команд разработки. Привязаны к конкретным неймспейсам.
- ClusterObservabilityPropagatedDashboard — универсальные дашборды, доступные всем пользователям.
Та же логика применяется к алертам: ClusterObservabilityMetricsAlertingRules, ObservabilityMetricsAlertingRules, ClusterObservabilityPropagatedMetricsAlertingRules.
Готовые дашборды и алерты «из коробки»
Платформа поставляется с набором готовых дашбордов и алертов — для всех собственных компонентов DKP и для типовых эксплуатационных сценариев: утилизация ресурсов, состояние сети, истечение срока сертификатов, ошибки ингрессов, недоступность образов в репозитории.
Отдельно стоит отметить отслеживание устаревших API в манифестах. Платформа заранее сигнализирует о таких местах, чтобы обновление Kubernetes не превращалось в инцидент.
Дашборды и алерты для операторов платформы
Для операторов платформы предусмотрены отдельные дашборды и алерты, покрывающие ключевые компоненты кластера. Они позволяют быстро оценить общее состояние инфраструктуры и увидеть проблемы, требующие внимания, — это утилизация ресурсов, состояние узлов, нехватка CPU и памяти, сетевые ошибки и другие сигналы, важные для стабильной работы кластера.
Предупреждения о проблемах до инцидентов
Помимо текущего состояния, DKP отслеживает потенциальные проблемы, которые могут проявиться позже. Например, использование устаревших (deprecated) API в манифестах. Платформа заранее сигнализирует о таких местах, чтобы обновления Kubernetes не превращались в инциденты.
Как это выглядит в работе
В DKP есть два глобально разных сценария использования. Первый — небольшая команда, которая отвечает и за кластер, и за приложения. Здесь жёсткое разделение прав не нужно, достаточно одного суперадминистратора с доступом ко всем разделам. Второй сценарий — крупная компания с отдельной платформенной командой и отдельными командами разработки. Вот тут разграничение становится принципиальным.
Что видит суперадминистратор
Когда заходишь в веб-интерфейс, первое, что видно, — общее состояние кластера: группы компонентов, их доступность, базовая утилизация ресурсов, состояние узлов. Если включено сканирование CVE (Common Vulnerabilities and Exposures), то его результаты тоже здесь. Раздел «Мониторинг» в левом меню открывает несколько подразделов.
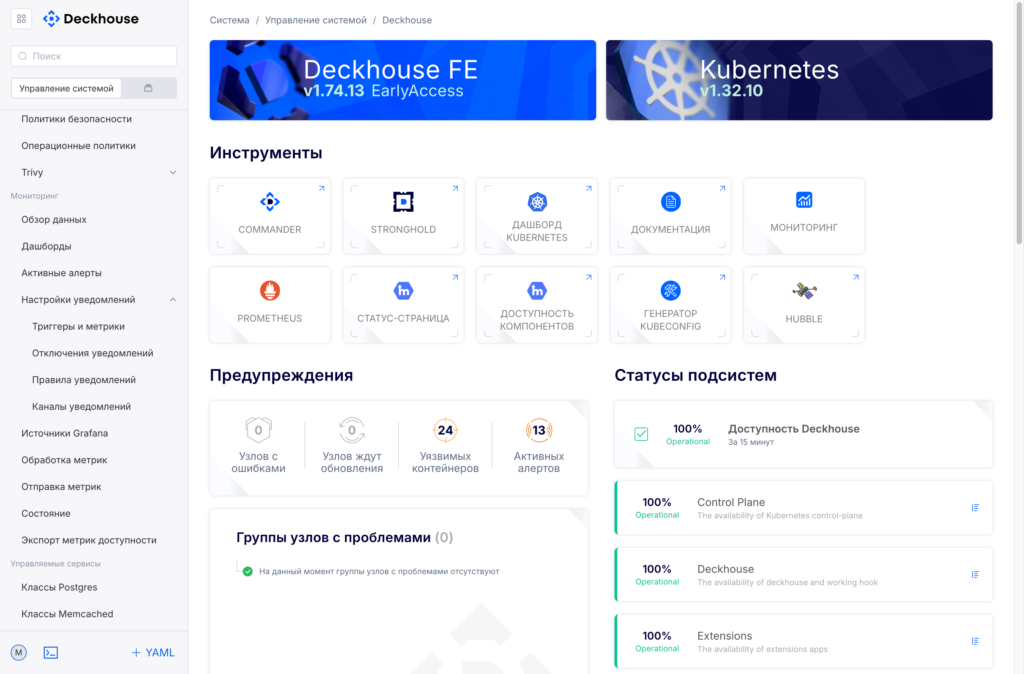
Обзор данных — прямые запросы в Prometheus, получение метрик без посредников.
Дашборды сгруппированы по папкам.
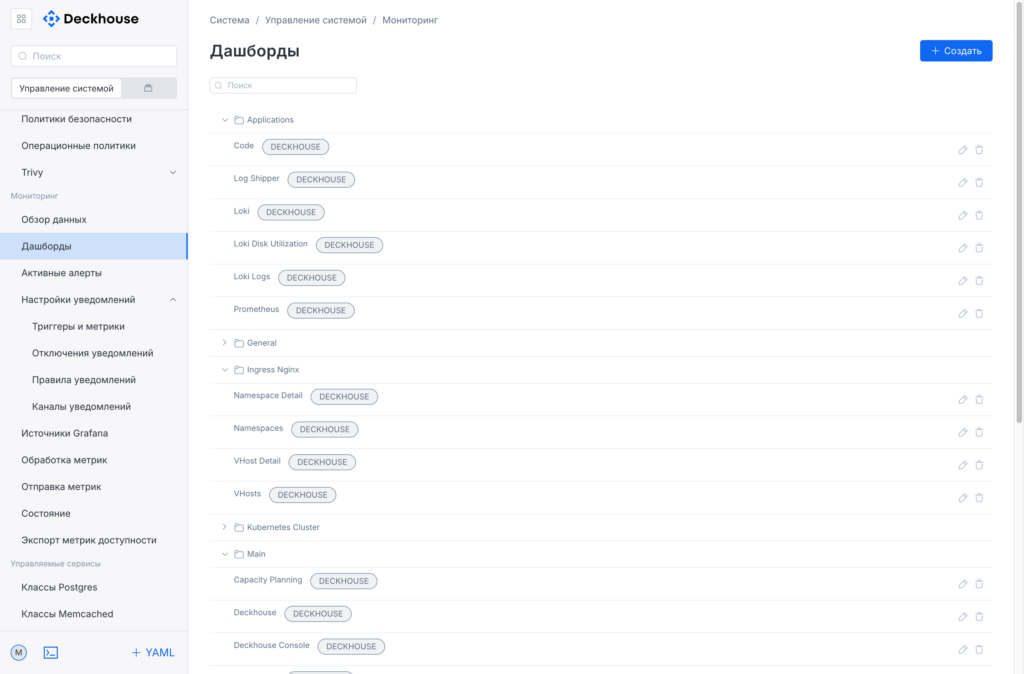
Универсальные дашборды по состоянию Ingress доступны всем. Отдельная папка — компоненты платформы (Kubernetes Cluster): Cilium, Deckhouse, DNS, etcd, Nginx Ingress Controller. Папка Main собирает дашборды по нагрузке подов. Там есть дашборд Namespaces, который показывает всё, что происходит во всех неймспейсах сразу: рестарты подов, потребление CPU, количество реплик. Из него можно выбрать конкретный неймспейс, провалиться до контроллеров, а оттуда — до отдельных подов.
Активные алерты — все текущие проблемы в одном месте. Каждый алерт можно раскрыть: там будут лейблы, график срабатывания, динамика метрики.
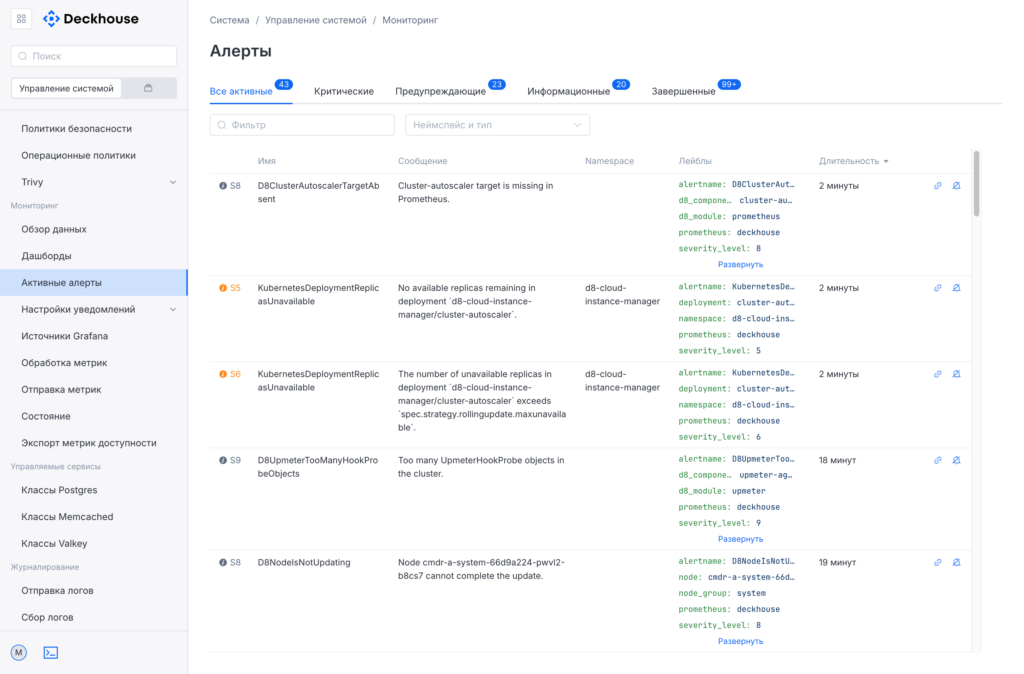
Настройка уведомлений делится на четыре части.
Триггеры и метрики — создание производных метрик из существующих. Это полезно, когда тяжёлые расчёты замедляют открытие дашбордов: их можно предпосчитать и хранить отдельно.
Отключение уведомлений — возможность временно заглушить алерты во время плановых работ.
Правила уведомлений — какие алерты идут по каким каналам.
Каналы уведомлений — настройка, куда доставлять алерты.
Источники Grafana — возможность подключения внешних источников данных: Elasticsearch, внешний Prometheus, Postgres.
Отправка метрик — настройка Prometheus Remote Write для передачи данных во внешнее долгосрочное хранилище.
Состояние — здесь видны инстансы, их загрузка, конфигурация модуля, флаги командной строки, статус TSDB, таргеты сбора метрик.
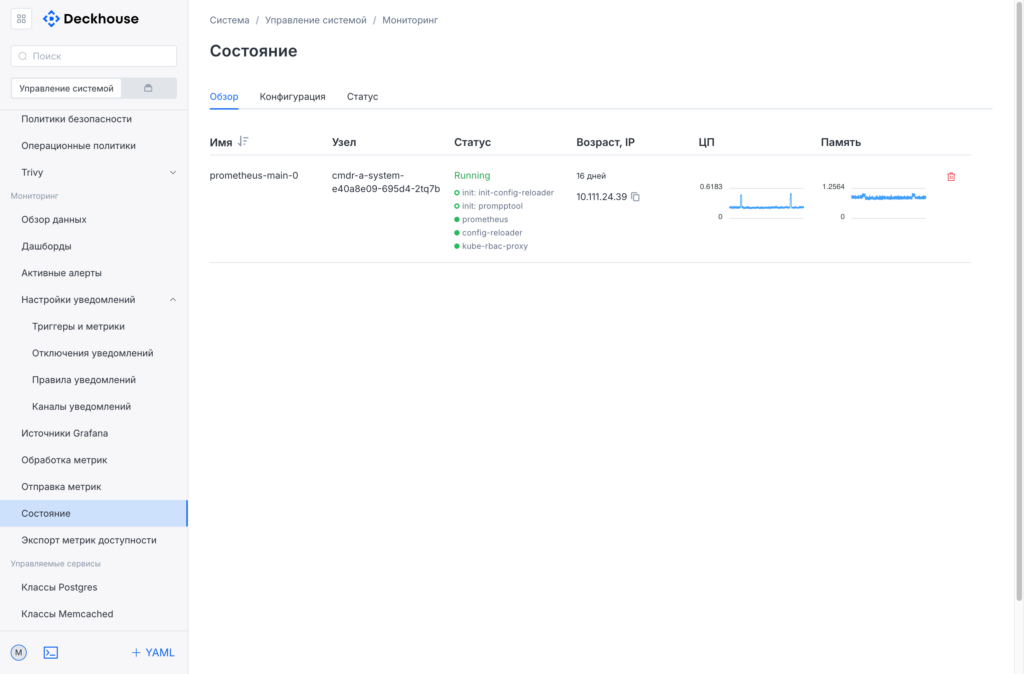
Важный момент: список таргетов зависит от прав пользователя. Оператор платформы не увидит пользовательские таргеты, пользователь — системные.
Экспорт метрик доступности. За общей статистикой по группам компонентов стоит отдельное приложение, которое каждую минуту прокручивает реальные пользовательские сценарии: проверяет, создаются ли поды, работают ли DNS, мониторинг, Ingress. Не просто «компонент запущен», а полноценное функциональное тестирование с замером времени и статуса. Эти метрики хранятся отдельно от Prometheus — как раз в этом разделе в том числе потому, что сам мониторинг тоже тестируется, — и могут отправляться во внешнюю систему через Remote Write.
Что видят оператор платформы и разработчик
Оператор платформы на первый взгляд видит тот же интерфейс. Но стоит перейти в проекты — пользовательские неймспейсы недоступны. При запросе метрик будут видны только данные с префиксами d8 и kube — служебные неймспейсы Deckhouse. К пользовательским данным доступа нет.
Разработчик приложений по умолчанию попадает в раздел «Система» — чтобы оценить общее состояние кластера и понять, не является ли проблема глобальной. В проектах доступен только его неймспейс. Набор дашбордов ограничен: универсальные (Ingress по нагрузке), политики безопасности (admission policy engine), дашборды для стандартных приложений, которые платформа умеет мониторить «из коробки». Дашборды Kubernetes-кластера недоступны. При запросе метрик и просмотре таргетов — только данные из своего неймспейса. Правила алертов пустые, пока команда не создаст собственные.
Доступно в Community Edition
Если захотите покрутить всё описанное руками — большая часть функционала доступна в бесплатной редакции Deckhouse CE. Правда, с небольшими ограничениями: интерфейс там в режиме read-only и управлять дашбордами придётся через консоль. Но для знакомства и экспериментов — самое то.
Все необходимые ссылки:
Хотите увидеть, как это работает вживую? В вебинаре мы подробно разобрали демостенд и ответили на вопросы зрителей. Запись можно посмотреть по ссылкам: YouTube, Rutube и VK Видео.