


























пресс-релиз
Deckhouse Observability Platform получила распределенный синтетический мониторинг доступности веб-сервисов
7 мая 2026
2 мин
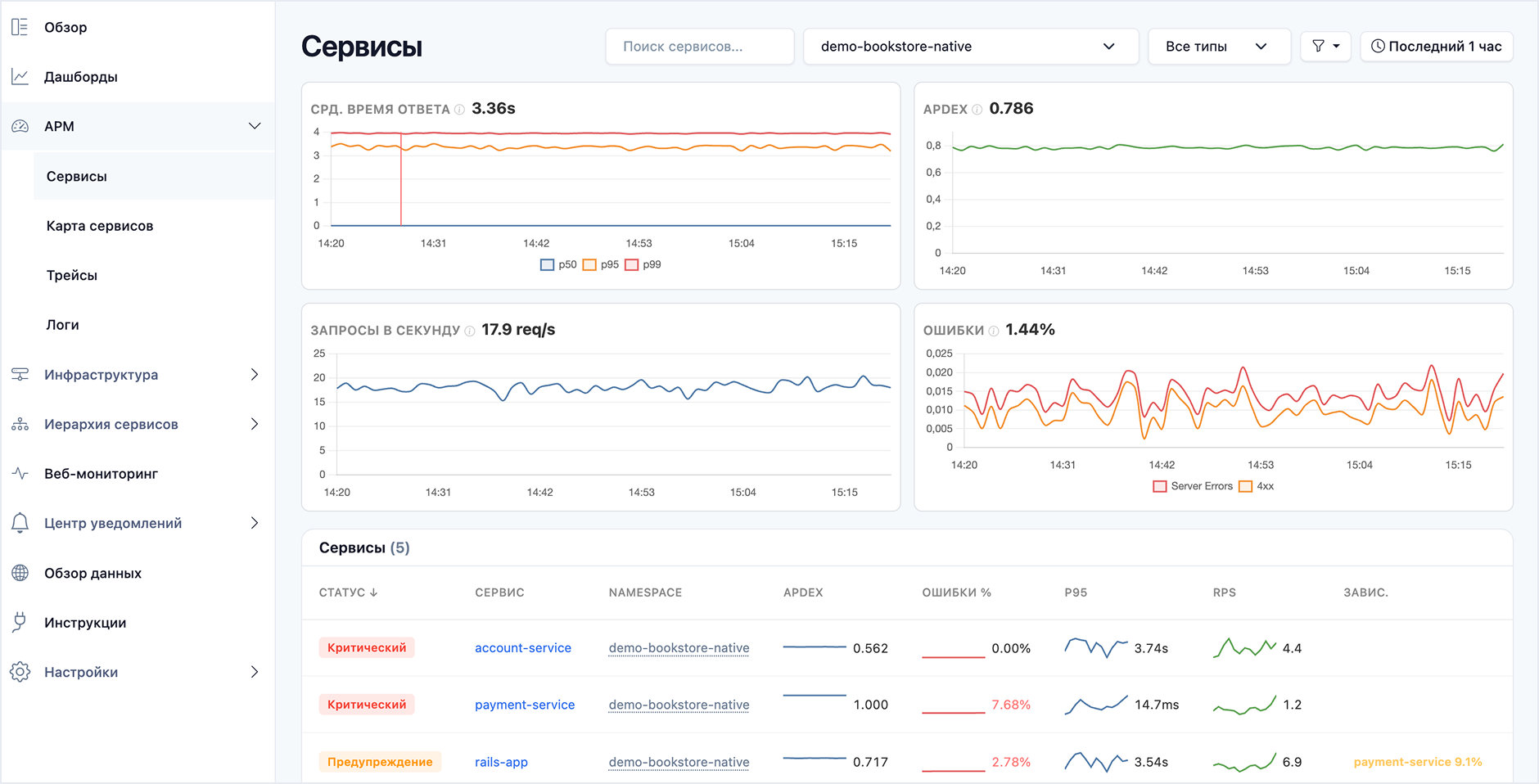
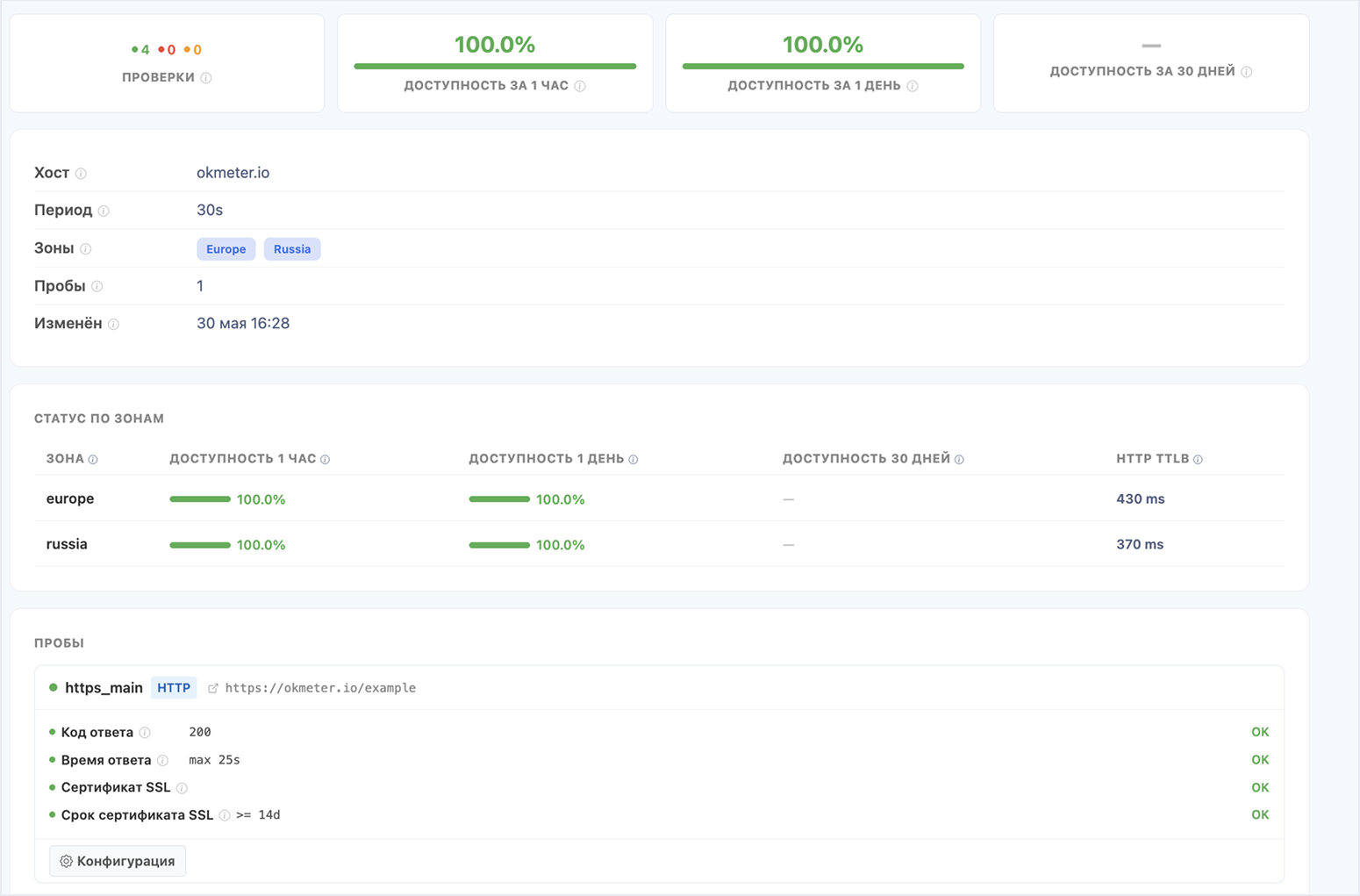
Теперь команды видят фактическую доступность веб-сервисов снаружи, из разных географических зон, и узнают о проблемах раньше пользователей

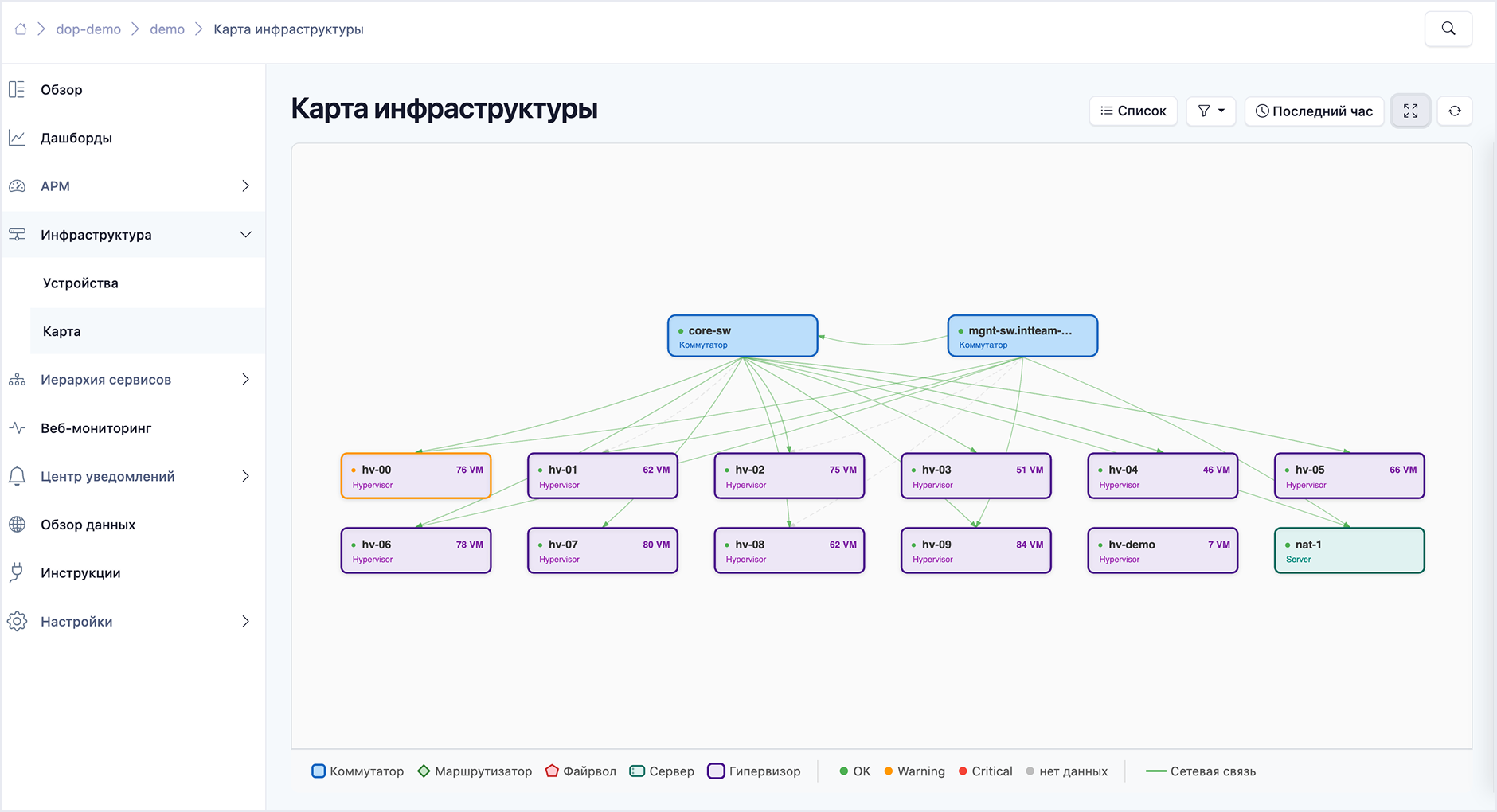
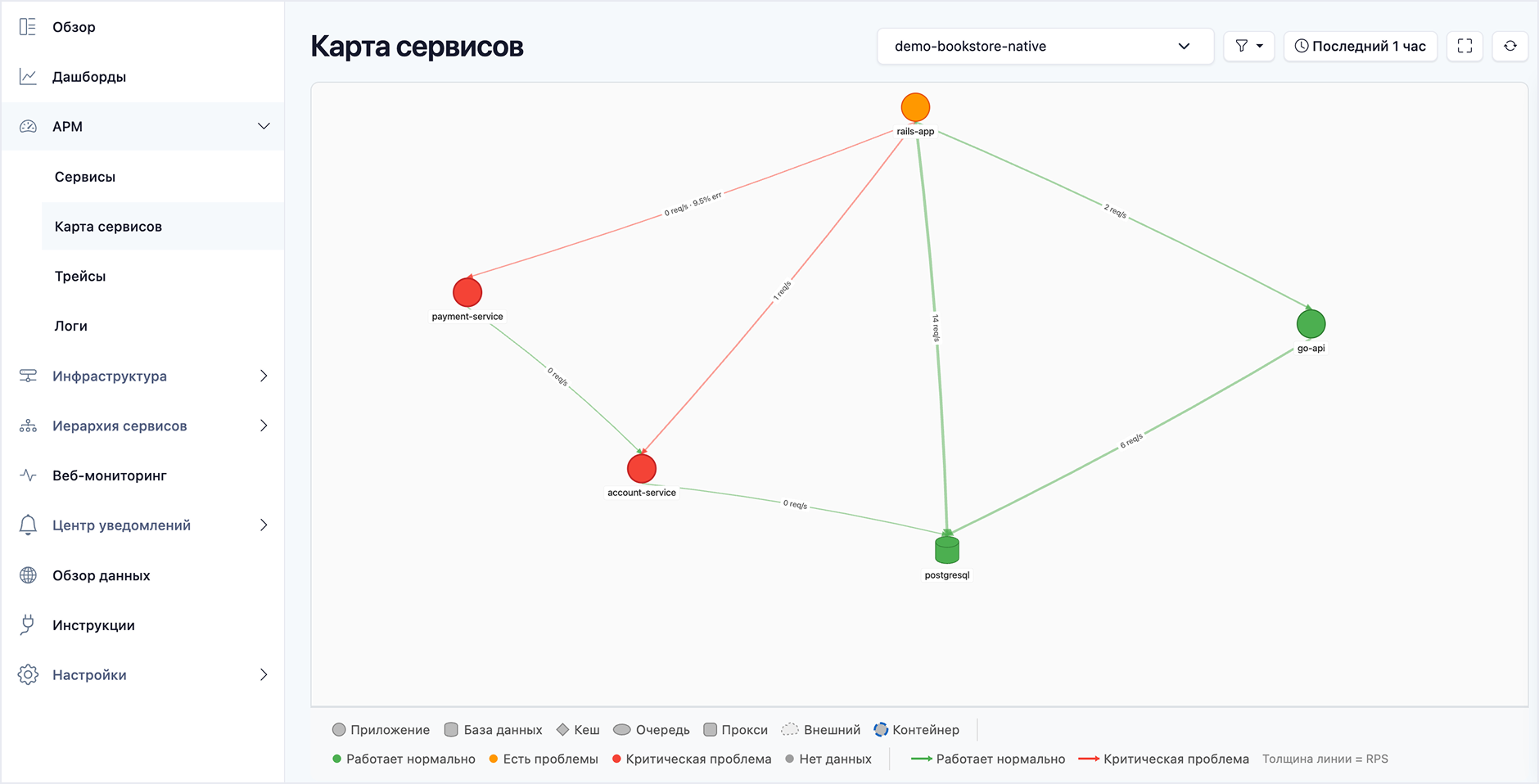
 Краткий обзор Deckhouse Observability Platform
Краткий обзор Deckhouse Observability Platform