Состав и схема взаимодействия компонентов мониторинга

Компоненты, устанавливаемые Deckhouse
| Компонент | Описание |
|---|---|
| prometheus-operator | Модуль Deckhouse, отвечающий за запуск Prometheus в кластере. |
| prometheus-main | Основной Prometheus, который выполняет scrape каждые 30 секунд (с помощью параметра scrapeInterval можно изменить это значение). Он обрабатывает все правила, отправляет алерты и является основным источником данных. |
| prometheus-longterm | Дополнительный Prometheus, хранящий выборку разреженных данных из основного prometheus-main |
| aggregating-proxy | Агрегирующий и кеширующий прокси, объединяющий main и longterm в один источник. Помогает избежать провалов в данных при недоступности одного из Prometheus. |
| memcached | Сервис кеширования данных в оперативной памяти. |
| grafana | UI для отображения метрик в формате дашбордов. |
| metrics-adapter | Компонент, предоставляющий API Kubernetes для доступа к метрикам. Необходим для правильной работы VPA. |
| Различные exporter’ы | Набор готовых exporter’ов Prometheus для всех необходимых метрик: kube-state-metrics, node-exporter, oomkill-exporter, image-availability-exporter. |
| upmeter | Модуль для оценки доступности компонентов DVP. |
| trickster | Кеширующий прокси, снижающий нагрузку на Prometheus. В ближайшем времени будет deprecated. |
Внешние компоненты
Deckhouse может интегрироваться с большим количеством разнообразных решений следующими способами:
| Название | Описание |
|---|---|
| Alertmanagers | Alertmanager’ы могут быть подключены к Prometheus и Grafana и находиться как в кластере Deckhouse, так и за его пределами. |
| Long-term metrics storages | Используя протокол remote write, возможно отсылать метрики из Deckhouse в большое количество хранилищ, включающее Cortex, Thanos, VictoriaMetrics. |
Prometheus
Prometheus собирает метрики и выполняет правила:
- Для каждого target (цели мониторинга) с заданной периодичностью
scrape_intervalPrometheus выполняет HTTP-запрос на этот target, получает в ответ метрики в собственном формате и сохраняет их в свою базу данных. - Каждый
evaluation_intervalобрабатывает правила (rules), на основании чего:- отправляет алерты;
- или сохраняет новые метрики (результат выполнения правил) в свою базу данных.
Prometheus устанавливается модулем prometheus-operator DVP, который выполняет следующие функции:
- определяет следующие кастомные ресурсы:
Prometheus— определяет инсталляцию (кластер) Prometheus;ServiceMonitor— определяет, как собирать метрики с сервисов;Alertmanager— определяет кластер Alertmanager‘ов;PrometheusRule— определяет список Prometheus rules.
- следит за этими ресурсами, а также:
- генерирует
StatefulSetс самим Prometheus; - создает секреты с необходимыми для работы Prometheus конфигурационными файлами (
prometheus.yaml— конфигурация Prometheus, иconfigmaps.json— конфигурация дляprometheus-config-reloader); - следит за ресурсами
ServiceMonitorиPrometheusRuleи на их основании обновляет конфигурационные файлы Prometheus через внесение изменений в секреты.
- генерирует
Что в поде с Prometheus?
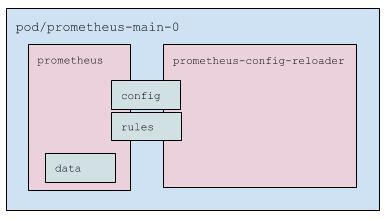
- Два контейнера:
prometheus— сам Prometheus;prometheus-config-reloader— обвязка, которая:- следит за изменениями
prometheus.yamlи, при необходимости, вызывает reload конфигурации Prometheus’у (специальным HTTP-запросом, см. подробнее ниже); - следит за PrometheusRule’ами (см. подробнее ниже) и по необходимости скачивает их и перезапускает Prometheus.
- следит за изменениями
- Pod использует три volume:
- config — примонтированный secret (два файла:
prometheus.yamlиconfigmaps.json). Подключен в оба контейнера; - rules —
emptyDir, который наполняетprometheus-config-reloader, а читаетprometheus. Подключен в оба контейнера, но вprometheusв режиме read only; - data — данные Prometheus. Подмонтирован только в
prometheus.
- config — примонтированный secret (два файла:
Как настраивается Prometheus?
- У сервера Prometheus есть config и есть rule files (файлы с правилами);
- В
configимеются следующие секции:scrape_configs— настройки поиска target’ов (целей для мониторинга, см. подробней следующий раздел);-
rule_files— список директорий, в которых лежат rule’ы, которые необходимо загружать:rule_files: - /etc/prometheus/rules/rules-0/* - /etc/prometheus/rules/rules-1/* alerting— настройки поиска Alert Manager’ов, в которые слать алерты. Секция очень похожа наscrape_configs, только результатом ее работы является список endpoint’ов, в которые Prometheus будет слать алерты.
Где Prometheus берет список target’ов?
-
В целом Prometheus работает следующим образом:
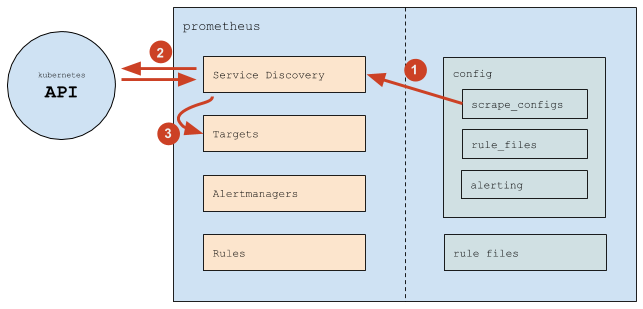
- (1) Prometheus читает секцию конфига
scrape_configs, согласно которой настраивает свой внутренний механизм Service Discovery; - (2) Механизм Service Discovery взаимодействует с API Kubernetes (в основном — получает endpoint`ы);
- (3) На основании происходящего в Kubernetes механизм Service Discovery обновляет Targets (список target’ов).
- (1) Prometheus читает секцию конфига
-
В
scrape_configsуказан список scrape job’ов (внутреннее понятие Prometheus), каждый из которых определяется следующим образом:scrape_configs: # Общие настройки - job_name: d8-monitoring/custom/0 # просто название scrape job'а, показывается в разделе Service Discovery scrape_interval: 30s # как часто собирать данные scrape_timeout: 10s # таймаут на запрос metrics_path: /metrics # path, который запрашивать scheme: http # http или https # Настройки service discovery kubernetes_sd_configs: # означает, что target'ы мы получаем из Kubernetes - api_server: null # означает, что адрес API-сервера использовать из переменных окружения (которые есть в каждом Pod'е) role: endpoints # target'ы брать из endpoint'ов namespaces: names: # искать endpoint'ы только в этих namespace'ах - foo - baz # Настройки "фильтрации" (какие enpoint'ы брать, а какие нет) и "релейблинга" (какие лейблы добавить или удалить, на все получаемые метрики) relabel_configs: # Фильтр по значению label'а prometheus_custom_target (полученного из связанного с endpoint'ом service'а) - source_labels: [__meta_kubernetes_service_label_prometheus_custom_target] regex: .+ # подходит любой НЕ пустой лейбл action: keep # Фильтр по имени порта - source_labels: [__meta_kubernetes_endpointslice_port_name] regex: http-metrics # подходит, только если порт называется http-metrics action: keep # Добавляем label job, используем значение label'а prometheus_custom_target у service'а, к которому добавляем префикс "custom-" # # Лейбл job это служебный лейбл Prometheus: # * он определяет название группы, в которой будет показываться target на странице targets # * и конечно же он будет у каждой метрики, полученной у этих target'ов, чтобы можно было удобно фильтровать в rule'ах и dashboard'ах - source_labels: [__meta_kubernetes_service_label_prometheus_custom_target] regex: (.*) target_label: job replacement: custom-$1 action: replace # Добавляем label namespace - source_labels: [__meta_kubernetes_namespace] regex: (.*) target_label: namespace replacement: $1 action: replace # Добавляем label service - source_labels: [__meta_kubernetes_service_name] regex: (.*) target_label: service replacement: $1 action: replace # Добавляем label instance (в котором будет имя Pod'а) - source_labels: [__meta_kubernetes_pod_name] regex: (.*) target_label: instance replacement: $1 action: replace - Таким образом, Prometheus сам отслеживает:
- добавление и удаление Pod’ов (при добавлении/удалении Pod’ов Kubernetes изменяет endpoint’ы, а Prometheus это видит и добавляет/удаляет target’ы);
- добавление и удаление сервисов (точнее endpoint’ов) в указанных пространствах имён;
- Изменение конфига требуется в следующих случаях:
- нужно добавить новый scrape config (обычно — новый вид сервисов, которые надо мониторить);
- нужно изменить список пространст имён.
Как обрабатываются Service Monitor’ы?
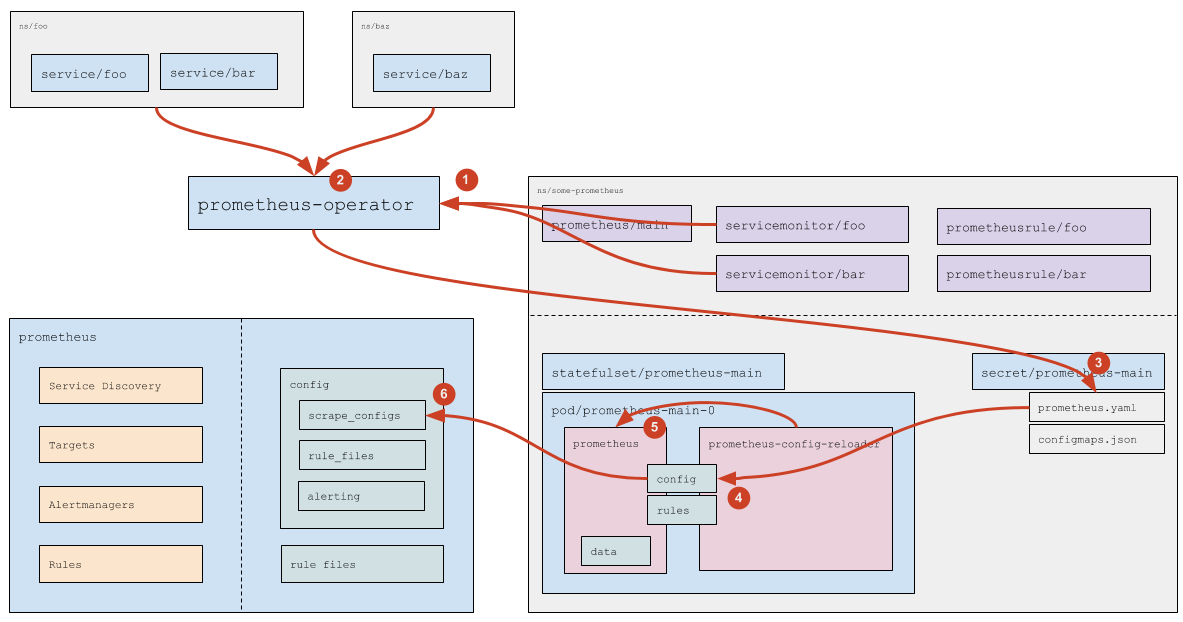
- Prometheus Operator читает (а также следит за добавлением/удалением/изменением) Service Monitor’ы (какие именно Service Monitor’ы — указано в самом ресурсе
prometheus, см. подробней официальную документацию). - Для каждого Service Monitor’а, если в нем НЕ указан конкретный список namespace’ов (указано
any: true), Prometheus Operator вычисляет (обращаясь к API Kubernetes) список namespace’ов, в которых есть Service’ы (подходящие под указанные в Service Monitor’е label’ы). - На основании прочитанных ресурсов
servicemonitor(см. официальную документацию) и на основании вычисленных namespace’ов Prometheus Operator генерирует часть конфига (секциюscrape_configs) и сохраняет конфиг в соответствующий Secret. - Штатными средствами самого Kubernetes данные из секрета прилетают в Pod (файл
prometheus.yamlобновляется). - Изменение файла замечает
prometheus-config-reloader, который по HTTP отправляет запрос Prometheus’у на перезагрузку. - Prometheus перечитывает конфиг и видит изменения в scrape_configs, которые обрабатывает уже согласно своей логике работы (см. подробнее выше).
Как обрабатываются кастомные ресурсы с rule’ами?
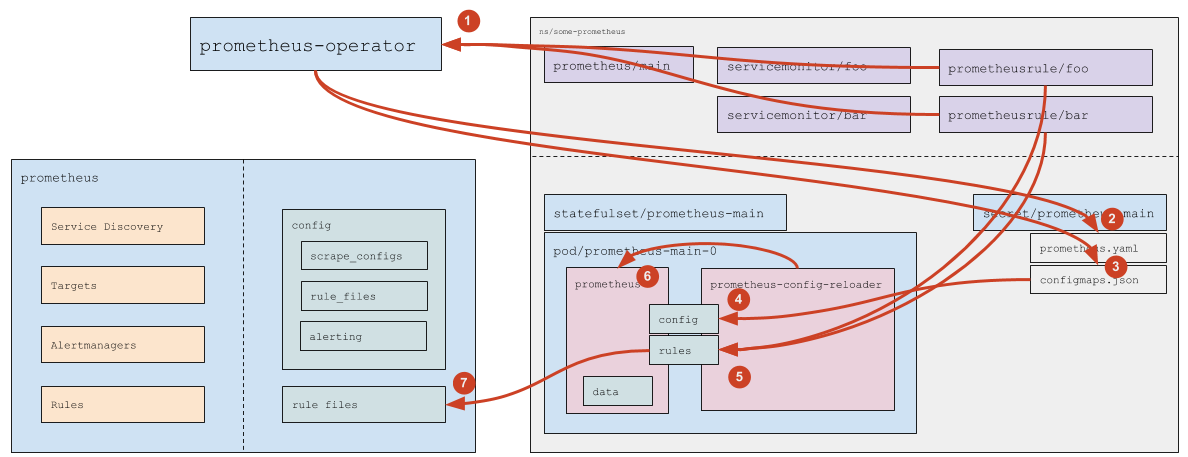
- Prometheus Operator следит за PrometheusRule’ами (подходящими под указанный в ресурсе
prometheusruleSelector). - Если появился новый (или был удален существующий) PrometheusRule — Prometheus Operator обновляет
prometheus.yaml(а дальше срабатывает логика в точности соответствующая обработке Service Monitor’ов, которая описана выше). - Как в случае добавления/удаления PrometheusRule’а, так и при изменении содержимого PrometheusRule’а, Prometheus Operator обновляет ConfigMap
prometheus-main-rulefiles-0. - Штатными средствами самого Kubernetes данные из ConfigMap прилетают в Pod
- Изменение файла замечает
prometheus-config-reloader, который:- скачивает изменившиеся ConfigMap’ы в директорию rules (это
emptyDir) - по HTTP отправляет запрос Prometheus’у на перезагрузку
- скачивает изменившиеся ConfigMap’ы в директорию rules (это
- Prometheus перечитывает конфиг и видит изменившиеся rule’ы.
Архитектура оценки доступности компонентов DVP (upmeter)
Оценка доступности в DVP осуществляется модулем upmeter.
Состав модуля upmeter:
- agent — работает на master-узлах и делает пробы доступности, отправляет результаты на сервер.
- upmeter — собирает результаты и поддерживает API-сервер для их извлечения.
- front:
- status — показывает уровень доступности за последние 10 минут (требует авторизации, но ее можно отключить);
- webui — показывает дашборд со статистикой по пробам и группам доступности (требует авторизации).
- smoke-mini — поддерживает постоянное smoke-тестирование с помощью StatefulSet.
Модуль отправляет около 100 показаний метрик каждые 5 минут. Это значение зависит от количества включенных модулей Deckhouse Virtualization Platform.