
Когда бизнес растёт, данные становятся сложнее, объёмнее и важнее для процессов внутри компаний. Однако вместо ускорения разработки и масштабирования компании сталкиваются с другим эффектом: инфраструктура всё чаще состоит из несовместимых компонентов, её стоимость увеличивается, а архитектура становится трудноуправляемой.
В этой статье разберём текущую ситуацию на рынке хранения и обработки данных, основные инфраструктурные вызовы и подход, реализованный в Deckhouse Data Orchestration.
Что происходит на рынке хранения и обработки данных
Инфраструктура хранения и обработки данных продолжает меняться. Крупные компании проходят этап цифровой трансформации: объёмы информации растут, внедряются ИИ-сценарии, увеличивается количество бизнес-сервисов. Всё чаще предприятия переходят к гибким архитектурам, ориентированным на частные и публичные облака. Такие среды предполагают self-service: инфраструктура разворачивается по запросу, без участия платформенных команд.
На фоне этих процессов усиливается влияние импортозамещения. Растёт количество отечественных решений — как аппаратных, так и программных. Появляются новые поставщики систем хранения данных (СХД) и серверов, обновляются линейки СУБД и аналитических систем. Это усложняет интеграции, снижает взаимную совместимость компонентов и требует пересмотра подходов к архитектуре.
Меняются и сами архитектурные модели. Классические Data Warehouse и Data Lake вытесняются форматом Lakehouse. Реляционные базы данных заменяются DBaaS-сервисами. Простые кэши уступают место DataGrid — более сложным и гибким in-memory-решениям. Одновременно растёт количество инструментов для аналитики, потоковой обработки и построения отчётности. Данные становятся полноценным ресурсом, с которым необходимо работать системно. Всё это формирует набор практических вызовов, с которыми сталкиваются компании при построении и развитии ИТ-среды.
С какими вызовами сталкивается инфраструктура сегодня
Первый вызов — рост стоимости хранения и вычислений
При увеличении объёмов данных и усложнении архитектур компании фиксируют рост как капитальных, так и операционных расходов. Усложняется найм специалистов — как системных, так и тех, кто работает с данными. При этом ресурсы используются неэффективно: часть инфраструктуры не задействуется, закупленные лицензии простаивают, а классический стек (например, Greenplum, Hadoop, MapReduce) становится тяжёлым в эксплуатации и плохо масштабируется. То же касается и обычных транзакционных баз — стоимость их обслуживания растёт, а утилизация ресурсов остаётся низкой.
Второй вызов — несоответствие архитектуры задачам бизнеса
Всё больше команд разработки ориентируется на ускорение процессов. Для этого они переходят на гибкие и облачные решения, используют подход self-service, выбирают DBaaS-модели. Однако, несмотря на то что такая архитектура выглядит технологически продвинутой, она может не справляться с реальной нагрузкой. И поставленные бизнесом задачи по скорости поставки новых продуктов часто невыполнимы из-за отсутствия качественной и продуманной системы работы с данными. В результате увеличивается Time to Market, снижается прогнозируемость, проседают пользовательские метрики и общая бизнес-эффективность.
Третий вызов — несовместимость компонентов
На практике аналитические движки могут не видеть данные в хранилищах, а базы — не поддерживать необходимые протоколы доступа. Аппаратные компоненты от разных вендоров не интегрируются без настройки, а архитектурные решения конфликтуют между собой. Даже обычные сценарии — например, выполнение select-запроса из базы данных — могут не работать из-за несовместимости ПО друг с другом и с аппаратной частью. Эта проблема усугубляется с ростом числа решений и отсутствием единого инфраструктурного стандарта.
Как Deckhouse Data Orchestration отвечает на эти вызовы
Data Orchestration — это новые модули Deckhouse, позволяющие создавать платформы хранения и обработки данных. Решение разработано как ответ на вызовы рынка.
Deckhouse Data Orchestration объединяет хранилище и вычисления в единую архитектуру и позволяет упростить инфраструктуру даже в условиях ограничений, связанных с локализацией, фрагментацией решений и отсутствием стандартизации. Всё это помогает оптимизировать ТСО, а также снизить капитальные и операционные затраты на ИТ-инфраструктуру как на этапе создания, так и в процессе эксплуатации.
Разделение Storage и Compute
Решение позволяет архитектурно разделять хранение данных и вычисления внутри одной инфраструктуры. Такой подход обеспечивает гибкость масштабирования, независимость ресурсов и лучшее использование существующего оборудования.
Ключевым элементом предоставляемой функциональности является MetaStore — сервис для управления метаданными, необходимыми в архитектуре Lakehouse. MetaStore включён в решение и работает «из коробки».
Единый слой хранения
Решение включает многофункциональный слой хранения, который объединяет различные типы СХД. Это могут быть:
- программно-определяемые хранилища (SDS);
- локальные диски (local storage);
- replicated volume;
- программно-аппаратные или аппаратные системы от отечественных и международных производителей — например, от «YADRO», «Аквариуса», Hitachi.
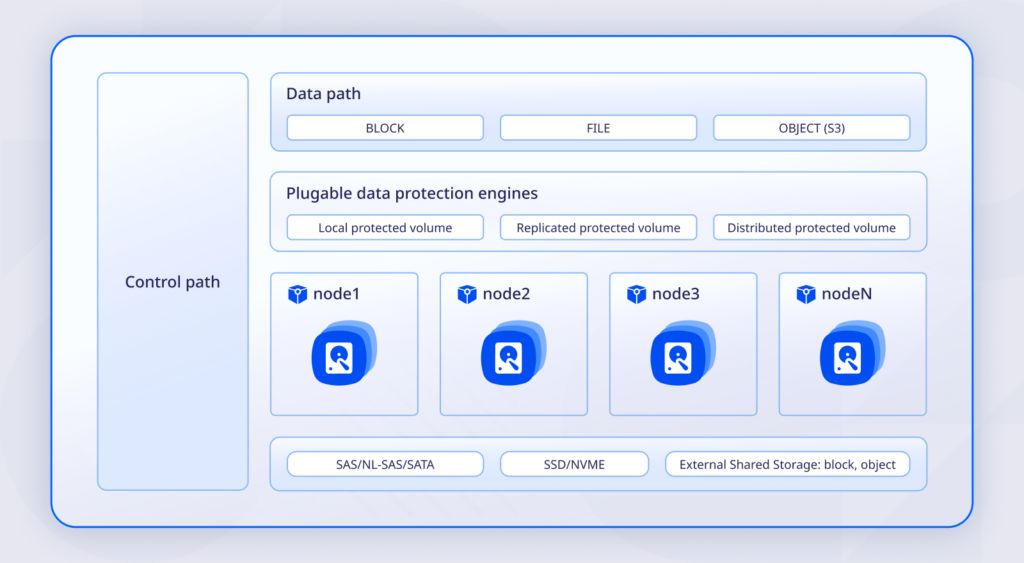
Поверх этих компонентов формируется мета-слой. Он позволяет создавать сервисы хранения декларативно — вы описываете нужные параметры, а система автоматически подбирает подходящую конфигурацию на доступных ресурсах.
Хранение может быть размещено как в локальном дата-центре, так и в любом другом кластере Deckhouse. Поддерживается подключение удалённых площадок, включая ресурсы сервис-провайдеров — они становятся частью общей инфраструктуры без дополнительных усилий со стороны команды эксплуатации.
Слой хранения масштабируется горизонтально и позволяет перемещать или реплицировать данные между кластерами. Это делает реализацию гибридных и геораспределённых сценариев значительно проще.
Унифицированное решение для хранилищ любой сложности
Решение позволяет разворачивать хранилища — аналитические и транзакционные — в любом кластере Deckhouse, независимо от его физического расположения. Хранение и вычисления могут выполняться как локально, так и удалённо. Это обеспечивает гибкость при масштабировании и снижает требования к локальной инфраструктуре.
Все вычисления над данными — аналитические запросы, ETL-процессы, агрегации или тренировка моделей — выполняются там, где есть ресурсы. Главное условие — развёрнутый кластер Deckhouse.
Поддерживаются также стандартизированные механизмы автоматизации. Это позволяет установить собственные или сторонние дистрибутивы ПО прямо в Deckhouse и создать отказоустойчивый сервис с минимальной ручной настройкой.
Все ключевые функции — бэкапы, мониторинг, управление доступом и аутентификация (IAM) — встроены в Deckhouse Kubernetes Platform и работают «из коробки».
Решение поддерживает как Open Source, так и Enterprise ПО от различных вендоров*:
- PostgreSQL, Cassandra, Redis;
- ClickHouse, Trino, StarRocks;
- Kafka, RabbitMQ;
- Spark, Flink, Airflow, Milvus;
- Cloudberry и другое.
Шаблоны архитектур под задачи бизнеса
Решение поддерживает шаблоны для развёртывания сложных сервисов. Речь идёт не о запуске одной базы данных, а о создании полноценной архитектуры из множества связанных компонентов. В шаблонах могут быть одновременно задействованы несколько баз данных, ETL-процессы, шины передачи данных и другие инфраструктурные элементы.
Эти шаблоны предназначены для типовых бизнес-сценариев и включают в себя лучшие практики. Команда Deckhouse может развернуть готовую, оптимизированную архитектуру, например, под автоматизированную банковскую систему, CRM, аналитическое хранилище, antifraud или систему отчётности.
ИИ-агенты
Deckhouse Data Orchestration включает встроенные ИИ-агенты, которые помогают автоматизировать эксплуатацию инфраструктуры. Они анализируют поведение сервисов, рекомендуют настройки, подсказывают оптимальные конфигурации и могут прогнозировать потенциальные сбои на основе собранных данных.
Решение также поддерживает хранение в памяти векторов и признаков (фич), необходимых для работы ML-моделей и векторных поисковиков.
Этот подход позволяет экономично выстраивать AI-инфраструктуру: за счёт переноса части нагрузки с GPU на традиционные CPU и оперативную память, архитектура становится доступнее и проще в сопровождении, особенно для inference-задач и realtime-ответов.
Технологическая инфраструктура с прикладной ценностью
Deckhouse Data Orchestration — это не просто инструмент для развёртывания хранилищ, а базовый архитектурный подход к управлению данными в современном ИТ-ландшафте. Решение позволяет сократить стоимость инфраструктуры, упростить сопровождение систем и повысить устойчивость распределённых сред.
В условиях импортозамещения, разнообразия оборудования и роста требований со стороны бизнеса становится критически важно иметь предсказуемую, отказоустойчивую и управляемую инфраструктуру. Вместо фрагментированных решений и сложной сборки из несовместимых компонентов — единая архитектура, готовая адаптироваться к будущим нагрузкам и требованиям.
*В роудмапе на 2026 год