Доступно в редакциях: CE, BE, SE, SE+, EE, CSE Lite (1.67), CSE Pro (1.67)
Стадия жизненного цикла модуля: General Availability
Как использовать extended-monitoring-exporter
Чтобы включить экспортирование extended-monitoring метрик, нужно указать в пространстве имён лейбл extended-monitoring.deckhouse.io/enabled любым удобным способом, например:
- добавить в проект соответствующий helm-чарт (рекомендуемый);
- добавить в описание
.gitlab-ci.yml(kubectl patch/create); - добавить вручную (
d8 k label namespace my-app-production extended-monitoring.deckhouse.io/enabled=""); - настроить через namespace-configurator модуль.
Сразу же после этого для всех поддерживаемых Kubernetes-объектов в данном пространстве имён в Prometheus появятся default-метрики + любые кастомные с префиксом threshold.extended-monitoring.deckhouse.io/. Для ряда non-namespaced Kubernetes-объектов, описанных ниже, мониторинг включается автоматически.
К Kubernetes-объектам threshold.extended-monitoring.deckhouse.io/что-то свое можно добавить любые другие лейблы с указанным значением. Пример: d8 k label pod test threshold.extended-monitoring.deckhouse.io/disk-inodes-warning=30.
В таком случае значение из лейбла заменит значение по умолчанию.
Если вы хотите переопределить значения threshold для всех объектов в определенном пространстве имен, вы можете установить лейбл threshold.extended-monitoring.deckhouse.io/ на уровне namespace. Например: d8 k label namespace my-app-production threshold.extended-monitoring.deckhouse.io/5xx-warning=20.
Это заменит значение по умолчанию для всех объектов namespace, для которых еще не установлен этот лейбл.
Слежение за объектом можно отключить индивидуально, поставив на него лейбл extended-monitoring.deckhouse.io/enabled=false. Соответственно, отключатся и лейблы по умолчанию, а также все алерты, привязанные к лейблам.
Стандартные лейблы и поддерживаемые Kubernetes-объекты
Далее приведен список используемых в Prometheus Rules лейблов, а также их стандартные значения.
Обратите внимание, что все лейблы начинаются с префикса threshold.extended-monitoring.deckhouse.io/. Указанное в лейбле значение — число, которое устанавливает порог срабатывания алерта.
Например, лейбл threshold.extended-monitoring.deckhouse.io/5xx-warning: "5" на Ingress-ресурсе изменяет порог срабатывания алерта с 10% (по умолчанию) на 5%.
Non-namespaced Kubernetes-объекты
Non-namespaced Kubernetes-объекты, то есть объекты вне пространств имён, не нуждаются в лейблах на этих пространствах и мониторинг на них включается по умолчанию при включении модуля.
Узел
| Лейбл | Тип | Значение по умолчанию |
|---|---|---|
| disk-bytes-warning | int (percent) | 70 |
| disk-bytes-critical | int (percent) | 80 |
| disk-inodes-warning | int (percent) | 90 |
| disk-inodes-critical | int (percent) | 95 |
| load-average-per-core-warning | int | 3 |
| load-average-per-core-critical | int | 10 |
Важно! Эти лейблы не действуют для тех разделов, в которых расположены
imagefs(по умолчанию —/var/lib/docker) иnodefs(по умолчанию —/var/lib/kubelet). Для этих разделов пороги настраиваются полностью автоматически согласно eviction thresholds в kubelet. Значения по умолчанию указаны в документации Kubernetes, в описании экспортера.
Namespaced Kubernetes-объекты
Под
| Лейбл | Тип | Значение по умолчанию |
|---|---|---|
| disk-bytes-warning | int (percent) | 85 |
| disk-bytes-critical | int (percent) | 95 |
| disk-inodes-warning | int (percent) | 85 |
| disk-inodes-critical | int (percent) | 90 |
Ingress
| Лейбл | Тип | Значение по умолчанию |
|---|---|---|
| 5xx-warning | int (percent) | 10 |
| 5xx-critical | int (percent) | 20 |
Deployment
| Лейбл | Тип | Значение по умолчанию |
|---|---|---|
| replicas-not-ready | int (count) | 0 |
Порог подразумевает количество недоступных реплик сверх maxUnavailable. Сработает, если недоступно реплик больше на указанное значение, чем разрешено в maxUnavailable. То есть при нуле сработает, если недоступно больше, чем указано в maxUnavailable, а при единице сработает, если недоступно больше, чем указано в maxUnavailable, плюс 1. Таким образом, у конкретных Deployment, которые находятся в пространстве имён со включенным расширенным мониторингом и которым допустимо быть недоступными, можно установить этот параметр, чтобы не получать ненужные алерты.
StatefulSet
| Лейбл | Тип | Значение по умолчанию |
|---|---|---|
| replicas-not-ready | int (count) | 0 |
Порог подразумевает количество недоступных реплик сверх maxUnavailable (см. комментарии к Deployment).
DaemonSet
| Лейбл | Тип | Значение по умолчанию |
|---|---|---|
| replicas-not-ready | int (count) | 0 |
Порог подразумевает количество недоступных реплик сверх maxUnavailable (см. комментарии к Deployment).
CronJob
Работает только выключение через лейбл extended-monitoring.deckhouse.io/enabled=false.
Как работает
Модуль экспортирует в Prometheus специальные лейблы Kubernetes-объектов. Позволяет улучшить Prometheus-правила путем добавления порога срабатывания для алертов. Использование метрик, экспортируемых данным модулем, позволяет, например, заменить «магические» константы в правилах.
До:
(
kube_statefulset_status_replicas - kube_statefulset_status_replicas_ready
)
> 1
После:
(
kube_statefulset_status_replicas - kube_statefulset_status_replicas_ready
)
> on (namespace, statefulset)
(
max by (namespace, statefulset) (extended_monitoring_statefulset_threshold{threshold="replicas-not-ready"})
)
В модуле реализовано 58 алертов.
Модуль включен по умолчанию в наборах модулей: Default, Managed.
Модуль выключен по умолчанию в наборе модулей Minimal.
Как явно включить или отключить модуль…
Явно включить или выключить модуль можно одним из следующих способов:
-
С помощью веб-интерфейса Deckhouse. В разделе «Система» → «Управление системой» → «Deckhouse» → «Модули», откройте модуль
extended-monitoring, включите (или выключите) переключатель «Модуль включен». Сохраните изменения.Пример:
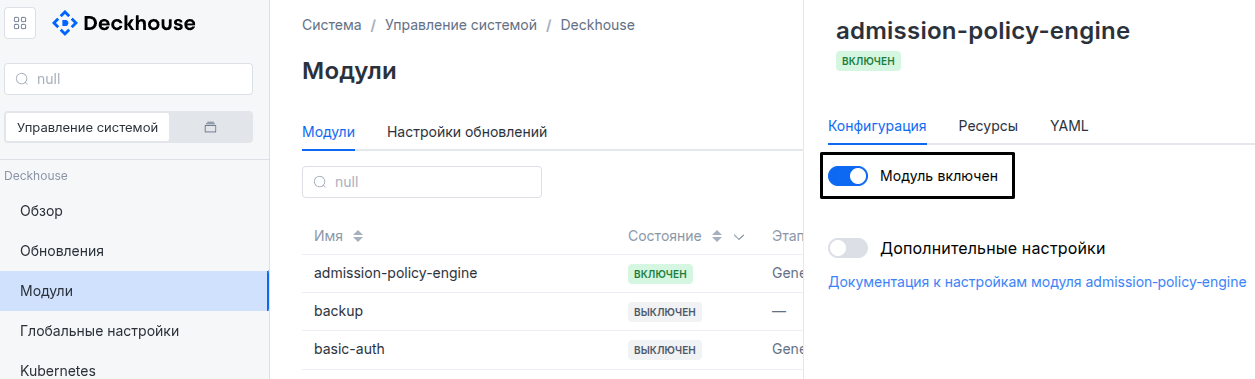
-
С помощью Deckhouse CLI (d8).
Используйте команду d8 system module enable для включения модуля, или d8 system module disable для выключения модуля (требуется Deckhouse CLI (d8), настроенный на работу с кластером).
Пример включения модуля
extended-monitoring:d8 system module enable extended-monitoring -
С помощью ModuleConfig
extended-monitoring.Установите
spec.enabledвtrueилиfalseв ModuleConfigextended-monitoring(создайте его, при необходимости).Пример манифеста для включения модуля
extended-monitoring:apiVersion: deckhouse.io/v1alpha1 kind: ModuleConfig metadata: name: extended-monitoring spec: enabled: true
Настроить модуль можно одним из следующих способов:
-
С помощью веб-интерфейса Deckhouse.
В разделе «Система» → «Управление системой» → «Deckhouse» → «Модули», откройте модуль
extended-monitoring, включите переключатель «Дополнительные настройки». Заполните необходимые поля формы на вкладке «Конфигурация», или укажите настройки модуля в формате YAML на вкладке «YAML», не включая секцию settings. Сохраните изменения.Пример:
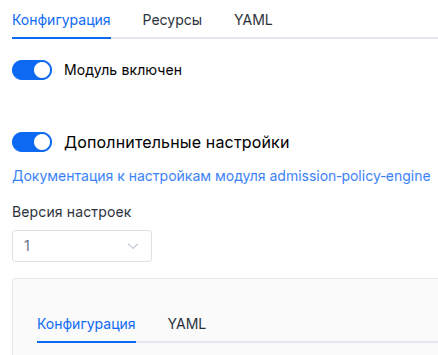
Вы также можете отредактировать объект ModuleConfig
extended-monitoringна вкладке «YAML» в окне настроек модуля («Система» → «Управление системой» → «Deckhouse» → «Модули», откройте модульextended-monitoring), указав версию схемы в параметреspec.versionи необходимые параметры модуля в секцииspec.settings. -
С помощью Deckhouse CLI (d8) (требуется Deckhouse CLI (d8), настроенный на работу с кластером).
Отредактируйте существующий ModuleConfig
extended-monitoring(подробнее о настройке Deckhouse читайте в документации), выполнив следующую команду:d8 k edit mc extended-monitoringВнесите необходимые изменения в секцию
spec.settings. При необходимости укажите версию схемы в параметреspec.version. Сохраните изменения.Вы также можете создать файл манифеста ModuleConfig
extended-monitoring, используя пример ниже. Заполните секциюspec.settingsнеобходимыми параметрами модуля. При необходимости укажите версию схемы в параметреspec.version.Примените манифест с помощью следующей команды (укажите имя файла манифеста):
d8 k apply -f <FILENAME>Пример файла манифеста ModuleConfig
extended-monitoring:apiVersion: deckhouse.io/v1alpha1 kind: ModuleConfig metadata: name: extended-monitoring spec: version: 2 enabled: true settings: # Параметры модуля из раздела "Параметры" ниже.
Требования
К версиям других модулей:
-
prometheus: любая версия.
Конверсии
Модуль настраивается с помощью ресурса ModuleConfig, схема которого содержит номер версии. При применении в кластере старой версии схемы ModuleConfig выполняются автоматические преобразования. Чтобы обновить версию схемы ModuleConfig вручную, необходимо последовательно для каждой версии выполнить следующие действия :
- Обновление из версии 1 в 2:
Если для поля
.imageAvailability.skipRegistryCertVerificationустановлено значениеtrue, добавьте поле.imageAvailability.registry.tlsConfig.insecureSkipVerify=true. После этого удалите поле.imageAvailability.skipRegistryCertVerificationиз объекта. Если в результате объект.imageAvailabilityстановится пуст, удалите его.
Параметры
Версия схемы: 2
- объектsettings
- объектsettings.certificates
Настройки для мониторинга сертификатов в кластере Kubernetes.
- булевыйsettings.certificates.exporterEnabled
Включен ли x509-certificate-exporter.
По умолчанию:
false
- объектsettings.events
Настройки для мониторинга event’ов в кластере Kubernetes.
- булевыйsettings.events.exporterEnabled
Включен ли eventsExporter.
По умолчанию:
false - строкаsettings.events.severityLevel
Enables eventsExporter.
По умолчанию:
OnlyWarningsДопустимые значения:
All,OnlyWarnings
- объектsettings.imageAvailability
Настройки для мониторинга доступности образов в кластере.
- булевыйsettings.imageAvailability.exporterEnabled
Включен ли imageAvailabilityExporter.
По умолчанию:
true - массив строкsettings.imageAvailability.forceCheckDisabledControllers
Список контроллеров, которые необходимо проверять, даже если количество реплик подов равняется 0 или контроллер находится в статусе
suspend(приостановленный).Укажите
All, для проверки всех типов контроллеров.Пример:
forceCheckDisabledControllers: - Deployment - StatefulSet- строкаЭлемент массива
Допустимые значения:
Deployment,StatefulSet,DaemonSet,CronJob,All
- массив строкsettings.imageAvailability.ignoredImages
Список образов, для которых нужно пропустить проверку, например
alpine:3.12илиquay.io/test/test:v1.1.Пример:
ignoredImages: - alpine:3.10 - alpine:3.2 - массив объектовsettings.imageAvailability.mirrors
Список зеркал для container registry.
Пример:
mirrors: - original: docker.io mirror: mirror.gcr.io - original: internal-registry.com mirror: mirror.internal-registry.com- строкаsettings.imageAvailability.mirrors.mirror
Обязательный параметр
- строкаsettings.imageAvailability.mirrors.original
Обязательный параметр
- объектsettings.imageAvailability.registry
Настройки подключения к container registry.
- строкаsettings.imageAvailability.registry.scheme
Протокол доступа к container registry.
По умолчанию:
HTTPSДопустимые значения:
HTTP,HTTPS - объектsettings.imageAvailability.registry.tlsConfig
Настройки подключения к container registry
- строкаsettings.imageAvailability.registry.tlsConfig.ca
Корневой сертификат, которым можно проверить сертификат container registry при работе по HTTPS (если registry использует самоподписанные SSL-сертификаты).
- булевыйsettings.imageAvailability.registry.tlsConfig.insecureSkipVerify
Пропускать ли валидацию TLS-сертификата для container registry.
По умолчанию:
false
- объектsettings.nodeSelector
Структура, аналогичная
spec.nodeSelectorпода Kubernetes.Если значение не указано или указано
false, будет использоваться автоматика. - массив объектовsettings.tolerations
Структура, аналогичная
spec.tolerationsпода Kubernetes.Если значение не указано или указано
false, будет использоваться автоматика.- строкаsettings.tolerations.effect
- строкаsettings.tolerations.key
- строкаsettings.tolerations.operator
- целочисленныйsettings.tolerations.tolerationSeconds
- строкаsettings.tolerations.value