














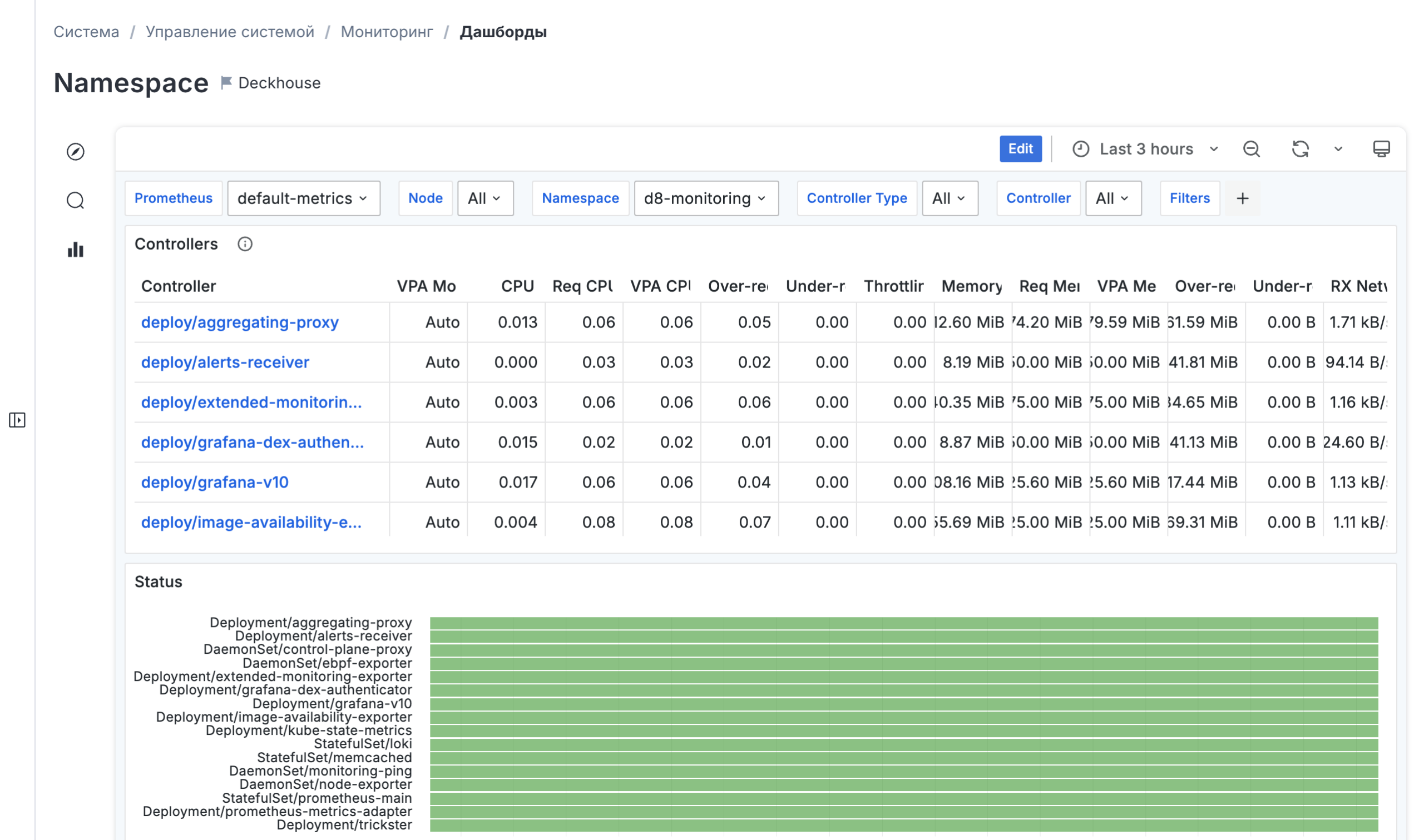





 Краткий обзор Наблюдаемость в Deckhouse Kubernetes Platform
Краткий обзор Наблюдаемость в Deckhouse Kubernetes Platform

пресс-релиз
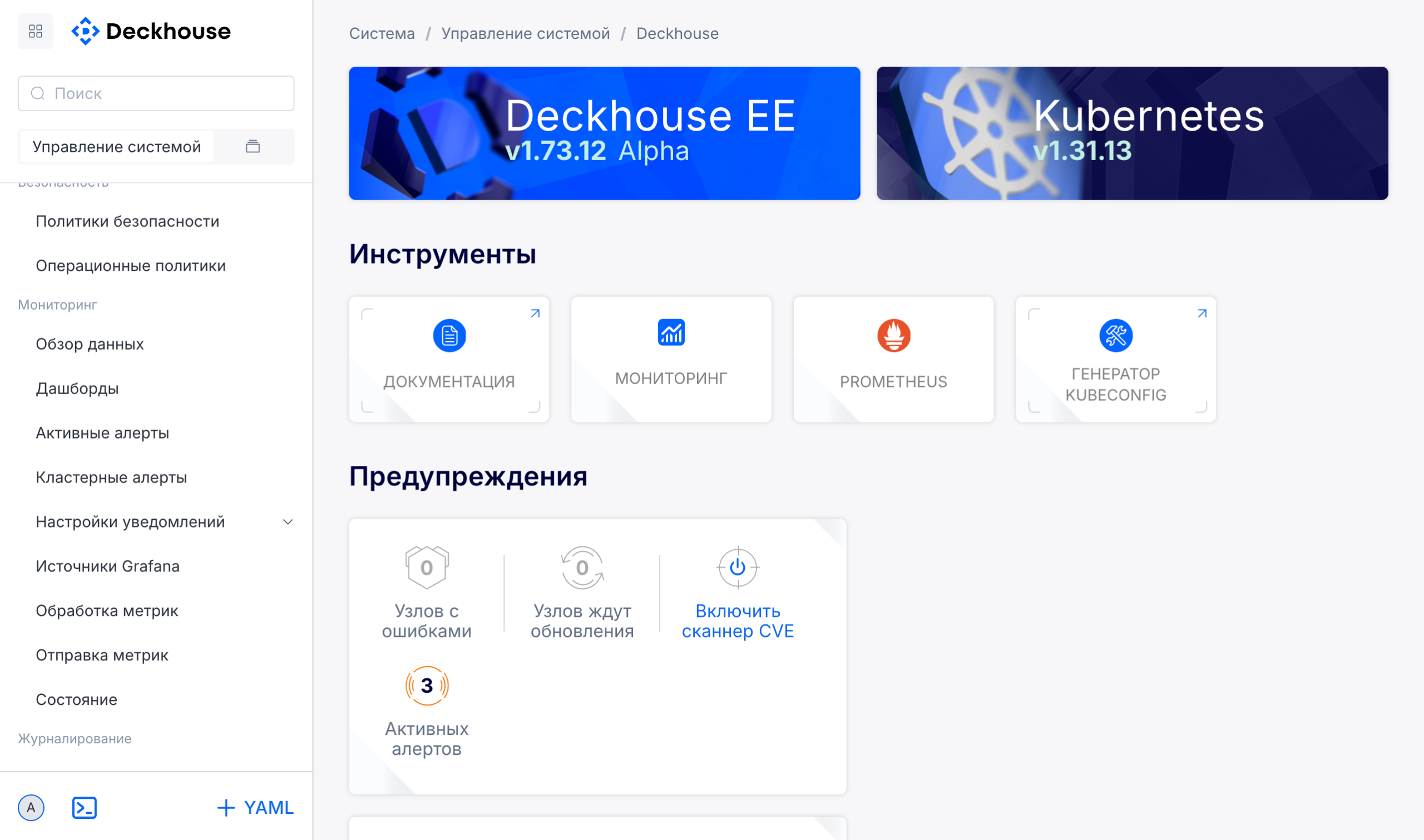
Deckhouse Kubernetes Platform получила встроенную систему мониторинга в веб-интерфейсе
24 декабря 2025
2 мин
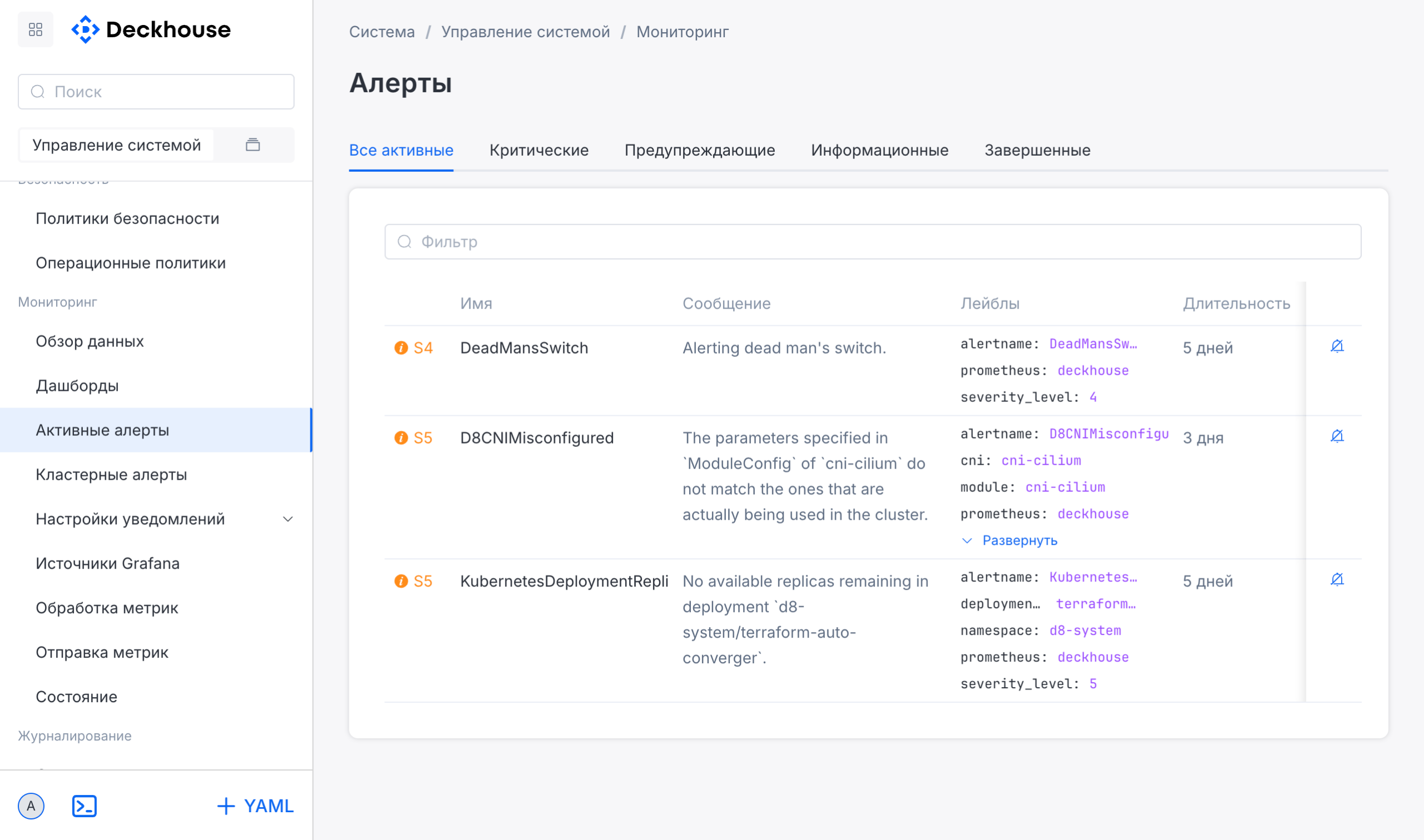
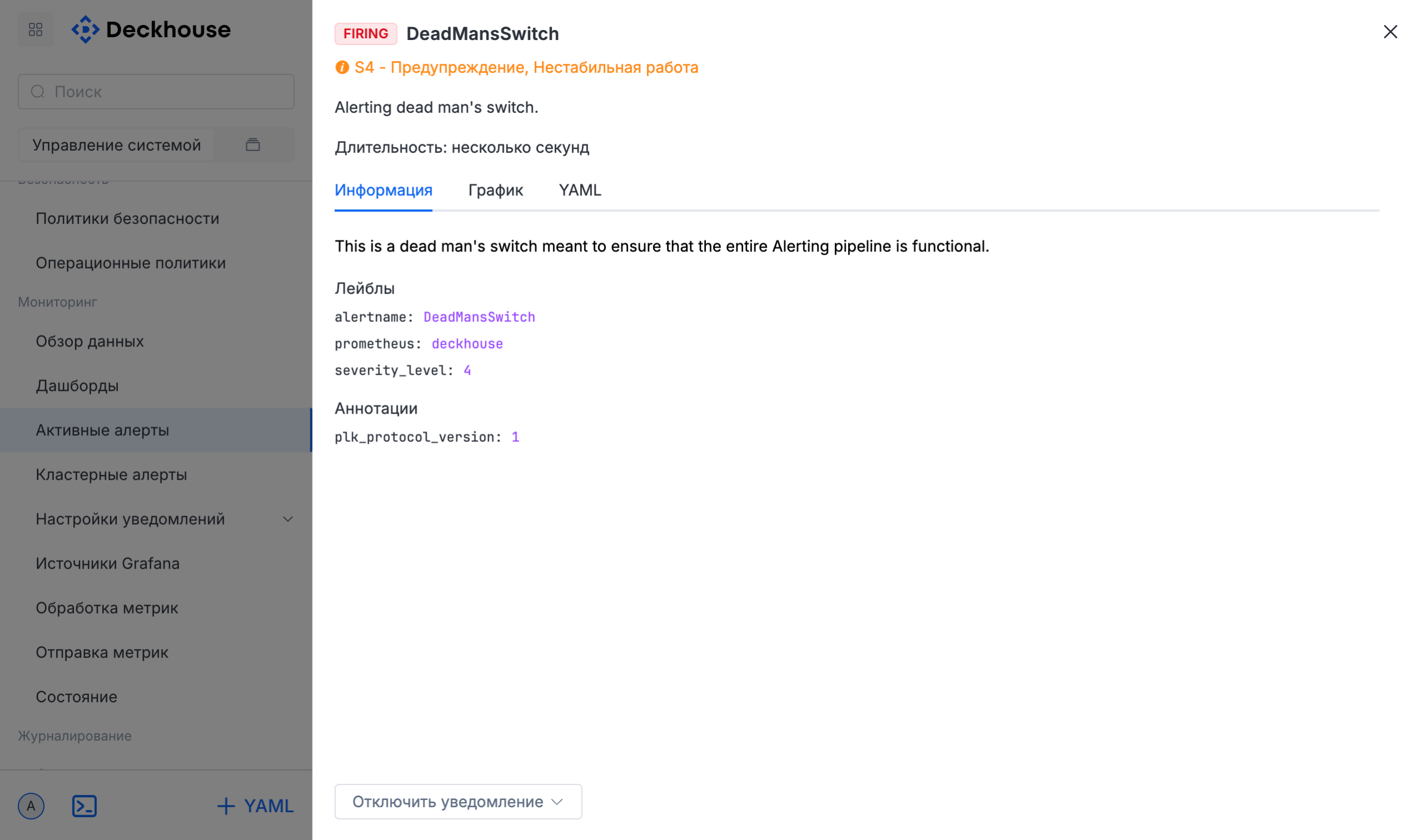
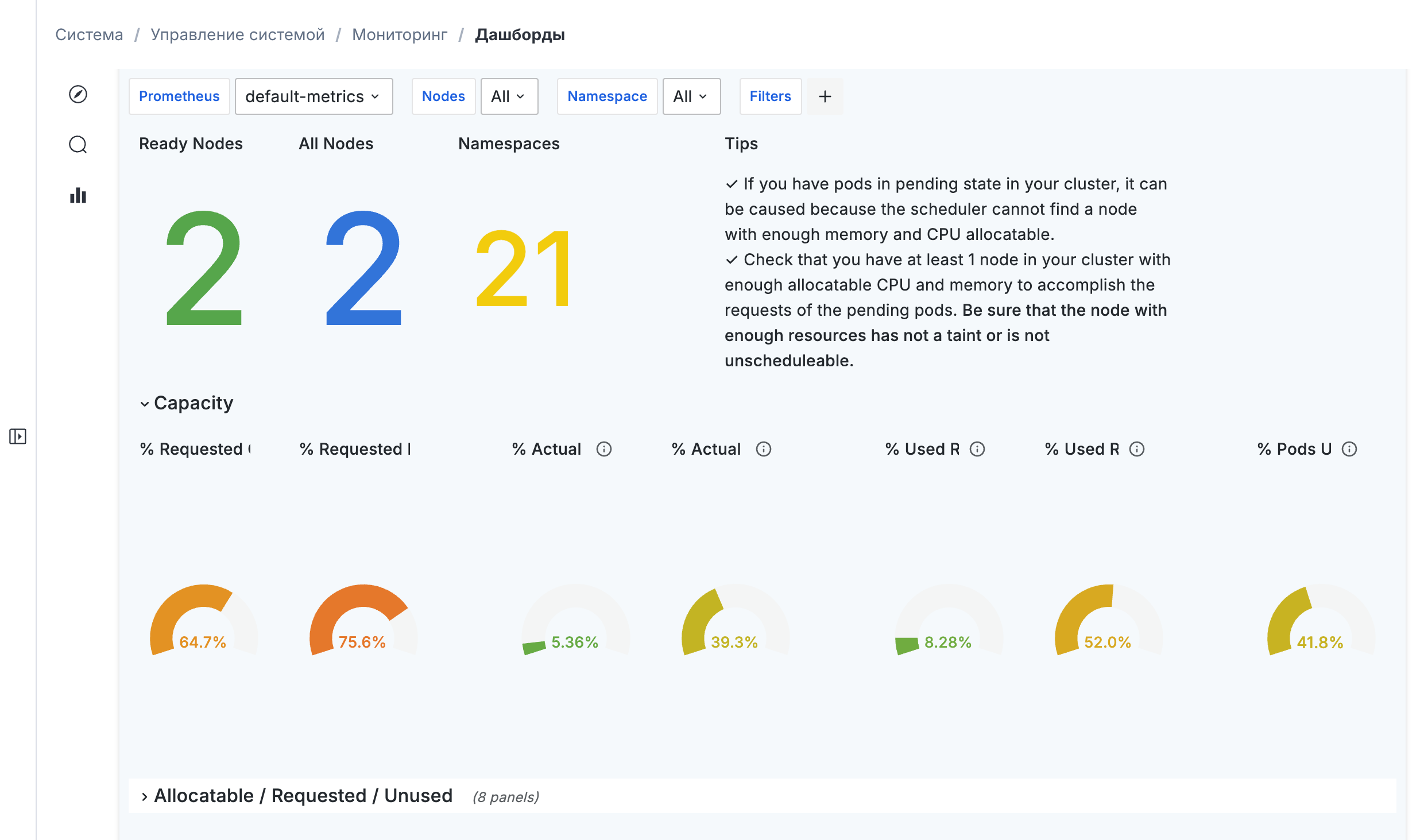
Система сквозного мониторинга встроена в платформу и отслеживает состояние всех компонентов инфраструктуры в режиме реального времени

