Механизмы обеспечения надежности
Миграция и режим обслуживания
Миграция виртуальных машин является важной функцией в управлении виртуализированной инфраструктурой. Она позволяет перемещать работающие виртуальные машины с одного физического узла на другой без их отключения. Миграция виртуальных машин необходима для ряда задач и сценариев:
- Балансировка нагрузки — перемещение виртуальных машин между узлами позволяет равномерно распределять нагрузку на серверы, обеспечивая использование ресурсов наилучшим образом.
- Перевод узла в режим обслуживания — виртуальные машины могут быть перемещены с узлов, которые нужно вывести из эксплуатации для выполнения планового обслуживания или обновления программного обеспечения.
- Обновление «прошивки» виртуальных машин — миграция позволяет обновить «прошивку» виртуальных машин, не прерывая их работу.
При живой миграции действуют следующие ограничения:
- С каждого узла одновременно может мигрировать только одна виртуальная машина.
- Одновременно в кластере может выполняться количество миграций, не превышающее число узлов, на которых разрешён запуск виртуальных машин.
- Пропускная способность для одной миграции ограничена 5 Гбит/с.
Запуск миграции произвольной машины
Далее будет рассмотрен пример миграции выбранной виртуальной машины.
-
Перед запуском миграции проверьте текущий статус виртуальной машины:
d8 k get vmПример вывода:
NAME PHASE NODE IPADDRESS AGE linux-vm Running virtlab-pt-1 10.66.10.14 79mМы видим, что на данный момент ВМ запущена на узле
virtlab-pt-1. -
Для осуществления миграции виртуальной машины с одного узла на другой, с учетом требований к размещению виртуальной машины используется ресурс VirtualMachineOperations (
vmop) с типомEvict. Создайте данный ресурс, следуя примеру:d8 k create -f - <<EOF apiVersion: virtualization.deckhouse.io/v1alpha2 kind: VirtualMachineOperation metadata: generateName: evict-linux-vm- spec: # Имя виртуальной машины. virtualMachineName: linux-vm # Операция для миграции. type: Evict EOF -
Сразу после создания ресурса
vmopвыполните команду:d8 k get vm -wПример вывода:
NAME PHASE NODE IPADDRESS AGE linux-vm Running virtlab-pt-1 10.66.10.14 79m linux-vm Migrating virtlab-pt-1 10.66.10.14 79m linux-vm Migrating virtlab-pt-1 10.66.10.14 79m linux-vm Running virtlab-pt-2 10.66.10.14 79m -
Если необходимо прервать миграцию, удалите соответствующий ресурс
vmop, пока он находится в фазеPendingилиInProgress.
Как запустить миграцию ВМ в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация» → «Виртуальные машины».
- Из списка выберите нужную виртуальную машину и нажмите кнопку с многоточием.
- Во всплывающем меню выберите
Мигрировать. - Во всплывающем окне подтвердите или отмените миграцию.
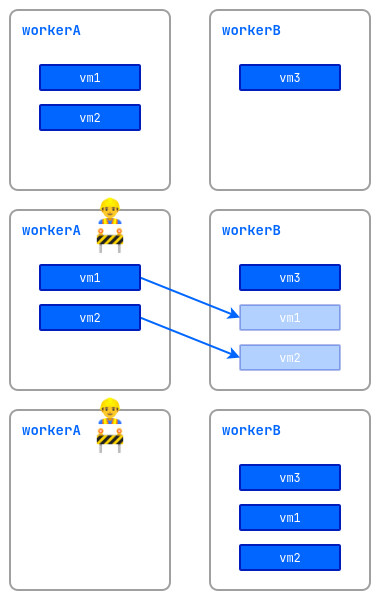
Режим обслуживания
При выполнении работ на узлах с запущенными виртуальными машинами существует риск нарушения их работоспособности. Чтобы этого избежать, узел можно перевести в режим обслуживания и мигрировать виртуальные машины на другие свободные узлы.
Для этого выполните следующую команду:
d8 k drain <nodename> --ignore-daemonsets --delete-emptydir-data
где <nodename> — узел, на котором предполагается выполнить работы и который должен быть освобождён от всех ресурсов (в том числе от системных).
Если необходимо вытеснить с узла только виртуальные машины, выполните следующую команду:
d8 k drain <nodename> --pod-selector vm.kubevirt.internal.virtualization.deckhouse.io/name --delete-emptydir-data
После выполнения команды d8 k drain узел перейдёт в режим обслуживания, и виртуальные машины на нём запускаться не смогут.
Чтобы вывести его из режима обслуживания, остановите выполнение команды drain (Ctrl+C), затем выполните:
d8 k uncordon <nodename>
Как выполнить операцию в веб-интерфейсе:
- Перейдите на вкладку «Система», далее в раздел «Узлы» → «Узлы всех групп».
- Из списка выберите нужный узел и нажмите кнопку «Сделать Cordon + Drain».
- Чтобы вывести его из режима обслуживания, нажмите кнопку «Uncordon».
Перебалансировка ВМ
Платформа позволяет автоматически управлять размещением работающих виртуальных машин в кластере. Чтобы включить эту функцию, активируйте модуль descheduler.
Для перебалансировки используется механизм живой миграции виртуальных машин между узлами кластера.
После активации модуля система самостоятельно следит за распределением виртуальных машин и поддерживает оптимальную загрузку узлов. Основные возможности модуля:
- Балансировка нагрузки — система отслеживает, сколько процессора зарезервировано на каждом узле. Если на каком-либо узле резервируется более 80% процессорных ресурсов, часть виртуальных машин будет автоматически перенесена на менее загруженные узлы. Это помогает избежать перегрузки и обеспечивает стабильную работу ВМ.
- Корректное размещение — система контролирует, соответствует ли текущий узел обязательным требованиям запросов виртуальной машины, а также правилам по их относительному расположению. Например, если правила не допускают размещения определённых ВМ на одном узле, модуль автоматически перенесёт их на подходящий сервер.
ColdStandby
ColdStandby обеспечивает механизм восстановления работы виртуальной машины после сбоя на узле, на котором она была запущена.
Для работы данного механизма необходимо выполнить следующие требования:
- Для политики запуска виртуальной машины (
.spec.runPolicy) должно быть установлено одно из следующих значений:AlwaysOnUnlessStoppedManually,AlwaysOn; - На узлах, где запущены виртуальные машины, должен быть включён механизм Fencing.
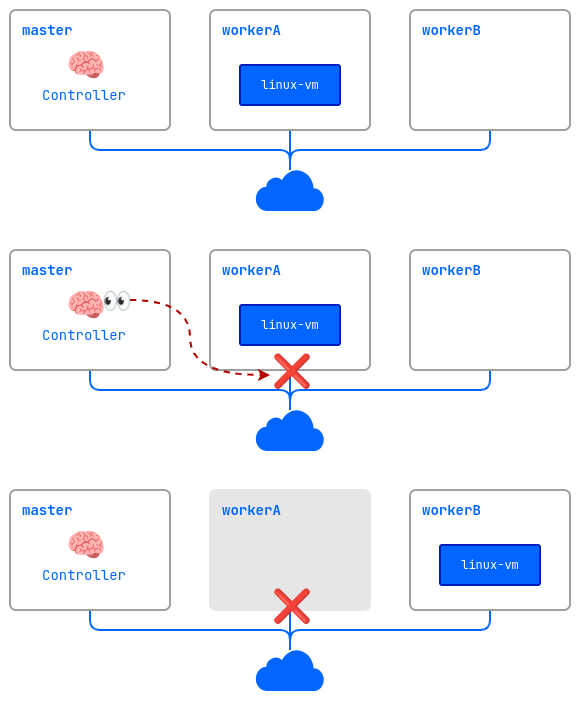
Рассмотрим как это работает на примере:
- Кластер состоит из трех узлов:
master,workerAиworkerB. На worker-узлах включён механизм Fencing. Виртуальная машинаlinux-vmзапущена на узлеworkerA. - На узле
workerAвозникает проблема (выключилось питание, пропала сеть, и т. д.). - Контроллер проверяет доступность узлов и обнаруживает, что
workerAнедоступен. - Контроллер удаляет узел
workerAиз кластера. - Виртуальная машина
linux-vmзапускается на другом подходящем узле (workerB).