Введение
Данное руководство предназначено для пользователей Deckhouse Virtualization Platform (DVP) и описывает порядок создания и изменения ресурсов, которые доступны для создания в проектах и неймспейсах кластера.
Быстрый старт по созданию ВМ
Пример создания виртуальной машины с Ubuntu 24.04.
-
Создайте образ виртуальной машины из внешнего источника:
d8 k apply -f - <<EOF apiVersion: virtualization.deckhouse.io/v1alpha2 kind: VirtualImage metadata: name: ubuntu spec: storage: ContainerRegistry dataSource: type: HTTP http: url: https://cloud-images.ubuntu.com/noble/current/noble-server-cloudimg-amd64.img EOFКак создать образ виртуальной машины из внешнего источника в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация» → «Образы дисков».
- Нажмите «Создать образ».
- Из списка выберите «Загрузить данные по ссылке (HTTP)».
- В открывшейся форме в поле «Имя образа» введите
ubuntu. - В поле «Хранилище» выберите
ContainerRegistry. - В поле «URL» вставьте
https://cloud-images.ubuntu.com/noble/current/noble-server-cloudimg-amd64.img. - Нажмите кнопку «Создать».
- Статус образа отображается слева вверху, под именем образа.
-
Создайте диск виртуальной машины из образа, созданного на предыдущем шаге (Внимание: перед созданием убедитесь, что в системе присутствует StorageClass по умолчанию):
d8 k apply -f - <<EOF apiVersion: virtualization.deckhouse.io/v1alpha2 kind: VirtualDisk metadata: name: linux-disk spec: dataSource: type: ObjectRef objectRef: kind: VirtualImage name: ubuntu EOFКак создать диск виртуальной машины из образа, созданного на предыдущем шаге, в веб-интерфейсе (данный шаг можно пропустить и выполнить при создании ВМ):
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация» → «Диски ВМ».
- Нажмите «Создать диск».
- В открывшейся форме в поле «Имя диска» введите
linux-disk. - В поле «Источник» убедитесь, что установлен чек-бокс «Проектные».
- Из выпадающего списка выберите
ubuntu. - В поле «Размер» можете изменить размер на больший, например на
5Gi. - В поле «Имя StorageClass» можно выбрать StorageClass или оставить выбранный по умолчанию.
- Нажмите кнопку «Создать».
- Статус диска отображается слева вверху, под именем диска.
Помните, если Ваш StorageClass имеет настройку WaitForFirstConsumer, диск будет ожидать создания ВМ с этим диском. Статус диска в этом случае
СОЗДАНИЕ 0%, но диск уже можно будет выбирать при создании ВМ, см. раздел диски -
Создайте виртуальную машину:
В примере используется cloud-init-сценарий для создания пользователя cloud с паролем cloud, сгенерированный следующим образом:
mkpasswd --method=SHA-512 --rounds=4096Изменить имя пользователя и пароль можно в этой секции:
users: - name: cloud passwd: $6$rounds=4096$G5VKZ1CVH5Ltj4wo$g.O5RgxYz64ScD5Ach5jeHS.Nm/SRys1JayngA269wjs/LrEJJAZXCIkc1010PZqhuOaQlANDVpIoeabvKK4j1Создайте виртуальную машину из следующей спецификации:
d8 k apply -f - <<'EOF' apiVersion: virtualization.deckhouse.io/v1alpha2 kind: VirtualMachine metadata: name: linux-vm spec: virtualMachineClassName: generic cpu: cores: 1 memory: size: 1Gi provisioning: type: UserData userData: | #cloud-config ssh_pwauth: True users: - name: cloud passwd: "$6$rounds=4096$saltsalt$fPmUsbjAuA7mnQNTajQM6ClhesyG0.yyQhvahas02ejfMAq1ykBo1RquzS0R6GgdIDlvS.kbUwDablGZKZcTP/" shell: /bin/bash sudo: ALL=(ALL) NOPASSWD:ALL lock_passwd: False blockDeviceRefs: - kind: VirtualDisk name: linux-disk EOFКак создать виртуальную машину в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация» → «Виртуальные машины»
- Нажмите «Создать».
- В открывшейся форме в поле «Имя» введите
linux-vm. - В разделе «Параметры машины» настройки можно оставить по умолчанию.
- В разделе «Диски и образы» в подразделе «Загрузочные диски» нажмите «Добавить».
Если вы уже создали диск:
- В открывшейся форме нажмите «Выбрать из существующих».
- В списке выберите диск
linux-disk.
Если вы не создавали диск:
- В открывшейся форме нажмите «Создать новый диск».
- В поле «Имя» введите
linux-disk. - В поле «Источник» нажмите на стрелку, чтобы развернуть список и убедитесь, что установлен чек-бокс «Проектные».
- Из выпадающего списка выберите
ubuntu. - В поле «Размер» можете изменить размер на больший, например на
5Gi. - В поле «Класс хранилища» можно выбрать StorageClass или оставить выбранный по умолчанию.
-
Нажмите кнопку «Создать и добавить».
- Прокрутите страницу вниз до раздела «Дополнительные параметры».
- Включите переключатель «Cloud-init».
- В появившееся поле вставьте ваши данные:
#cloud-config ssh_pwauth: True users: - name: cloud passwd: "$6$rounds=4096$saltsalt$fPmUsbjAuA7mnQNTajQM6ClhesyG0.yyQhvahas02ejfMAq1ykBo1RquzS0R6GgdIDlvS.kbUwDablGZKZcTP/" shell: /bin/bash sudo: ALL=(ALL) NOPASSWD:ALL lock_passwd: False- Нажмите кнопку «Создать».
- Статус ВМ отображается слева вверху, под ее именем.
Полезные ссылки:
-
Проверьте с помощью команды, что образ и диск созданы, а виртуальная машина запущена. Ресурсы создаются не мгновенно, поэтому прежде чем они перейдут в готовое состояние потребуется подождать какое-то время.
d8 k get vi,vd,vmПример вывода:
NAME PHASE CDROM PROGRESS AGE virtualimage.virtualization.deckhouse.io/ubuntu Ready false 100% # NAME PHASE CAPACITY AGE virtualdisk.virtualization.deckhouse.io/linux-disk Ready 300Mi 7h40m # NAME PHASE NODE IPADDRESS AGE virtualmachine.virtualization.deckhouse.io/linux-vm Running virtlab-pt-2 10.66.10.2 7h46m -
Подключитесь с помощью консоли к виртуальной машине (для выхода из консоли необходимо нажать
Ctrl+]):d8 v console linux-vmПример вывода:
Successfully connected to linux-vm console. The escape sequence is ^] # linux-vm login: cloud Password: cloud ... cloud@linux-vm:~$Как подключиться к виртуальной машине с помощью консоли в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация” -> «Виртуальные машины»
- Из списка выберите необходимую ВМ и нажмите на её имя.
- В открывшейся форме перейдите на вкладку «TTY»
- Перейдите в открывшееся окно консоли. Здесь можно подключиться к ВМ.
-
Для удаления созданных ранее ресурсов используйте следующие команды:
d8 k delete vm linux-vm d8 k delete vd linux-disk d8 k delete vi ubuntu
Виртуальные машины
Для создания виртуальной машины используется ресурс VirtualMachine. Его параметры позволяют сконфигурировать:
- класс виртуальной машины;
- ресурсы, требуемые для работы виртуальной машины (процессор, память, диски и образы);
- правила размещения виртуальной машины на узлах кластера;
- настройки загрузчика и оптимальные параметры для гостевой ОС;
- политику запуска виртуальной машины и политику применения изменений;
- сценарии начальной конфигурации (cloud-init);
- перечень блочных устройств.
С полным описанием параметров конфигурации виртуальных машин можно ознакомиться по в документации конфигурации.
Создание виртуальной машины
Ниже представлен пример конфигурации виртуальной машины, запускающей ОС Ubuntu 24.04. В примере используется сценарий первичной инициализации виртуальной машины (cloud-init), который устанавливает гостевого агента qemu-guest-agent и сервис nginx, а также создает пользователя cloud с паролем cloud:
Пароль в примере был сгенерирован с использованием команды mkpasswd --method=SHA-512 --rounds=4096 -S saltsalt и при необходимости вы можете его поменять на свой:
Создайте виртуальную машину с диском созданным ранее:
d8 k apply -f - <<'EOF'
apiVersion: virtualization.deckhouse.io/v1alpha2
kind: VirtualMachine
metadata:
name: linux-vm
spec:
# Название класса ВМ.
virtualMachineClassName: generic
# Тип ОС (Generic для Linux, Windows для Windows). По умолчанию: Generic.
# osType: Generic
# Тип загрузчика (BIOS, EFI, EFIWithSecureBoot). По умолчанию: BIOS.
# bootloader: BIOS
# Блок скриптов первичной инициализации ВМ.
provisioning:
type: UserData
# Пример cloud-init-сценария для создания пользователя cloud с паролем cloud и установки сервиса агента qemu-guest-agent и сервиса nginx.
userData: |
#cloud-config
package_update: true
packages:
- nginx
- qemu-guest-agent
runcmd:
- systemctl daemon-reload
- systemctl enable --now nginx.service
- systemctl enable --now qemu-guest-agent.service
ssh_pwauth: True
users:
- name: cloud
passwd: "$6$rounds=4096$saltsalt$fPmUsbjAuA7mnQNTajQM6ClhesyG0.yyQhvahas02ejfMAq1ykBo1RquzS0R6GgdIDlvS.kbUwDablGZKZcTP/"
shell: /bin/bash
sudo: ALL=(ALL) NOPASSWD:ALL
lock_passwd: False
final_message: "The system is finally up, after $UPTIME seconds"
# Настройки ресурсов ВМ.
cpu:
# Количество ядер ЦП.
cores: 1
# Запросить 10% процессорного времени одного физического ядра.
coreFraction: 10%
memory:
# Объем оперативной памяти.
size: 1Gi
# Список дисков и образов, используемых в ВМ.
blockDeviceRefs:
# Порядок дисков и образов в данном блоке определяет приоритет загрузки.
- kind: VirtualDisk
name: linux-vm-root
EOF
Проверьте состояние виртуальной машины после создания:
d8 k get vm linux-vm
Пример вывода:
NAME PHASE NODE IPADDRESS AGE
linux-vm Running virtlab-pt-2 10.66.10.12 11m
После создания виртуальная машина автоматически получит IP-адрес из диапазона, указанного в настройках модуля (блок virtualMachineCIDRs).
Как создать виртуальную машину в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация» → «Виртуальные машины».
- Нажмите «Создать».
- В открывшейся форме в поле «Имя» введите
linux-vm. - В разделе «Параметры машины» в поле «Ядер» задайте
1. - В разделе «Параметры машины» в поле «Доля ЦП» задайте
10%. - В разделе «Параметры машины» в поле «Размер» задайте
1Gi. - В разделе «Диски и образы» в подразделе «Загрузочные диски» нажмите «Добавить».
- В открывшейся форме нажмите «Выбрать из существующих».
- В списке выберите диск
linux-vm-root. - Прокрутите страницу вниз до раздела «Дополнительные параметры».
- Включите переключатель «Cloud-init».
-
В появившееся поле вставьте ваши данные:
#cloud-config package_update: true packages: - nginx - qemu-guest-agent runcmd: - systemctl daemon-reload - systemctl enable --now nginx.service - systemctl enable --now qemu-guest-agent.service ssh_pwauth: True users: - name: cloud passwd: "$6$rounds=4096$saltsalt$fPmUsbjAuA7mnQNTajQM6ClhesyG0.yyQhvahas02ejfMAq1ykBo1RquzS0R6GgdIDlvS.kbUwDablGZKZcTP/" shell: /bin/bash sudo: ALL=(ALL) NOPASSWD:ALL lock_passwd: False final_message: "The system is finally up, after $UPTIME seconds" - Нажмите кнопку «Создать».
- Статус ВМ отображается слева вверху, под ее именем.
Жизненный цикл ВМ
Виртуальная машина проходит через несколько этапов своего существования — от создания до удаления. Эти этапы называются фазами и отражают текущее состояние ВМ. Чтобы понять, что происходит с ВМ, нужно проверить её статус (поле .status.phase), а для более детальной информации — блок .status.conditions. Ниже описаны все основные фазы жизненного цикла ВМ, их значение и особенности.
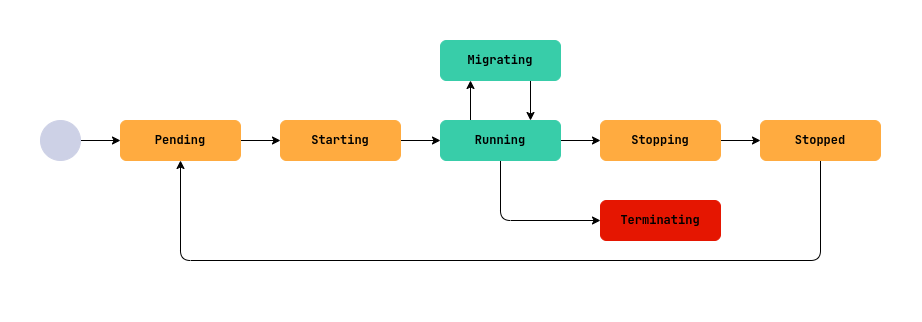
-
Pending— ожидание готовности ресурсов.ВМ только что создана, перезапущена или запущена после остановки и ожидает готовности необходимых ресурсов (дисков, образов, ip-адресов и т.д.).
- Возможные проблемы:
- не готовы зависимые ресурсы: диски, образы, классы ВМ, секрет со сценарием начальной конфигурации и пр.
-
Диагностика: В
.status.conditionsстоит обратить внимание на условия*Ready. По ним можно определить, что блокирует переход к следующей фазе, например, ожидание готовности дисков (BlockDevicesReady) или класса ВМ (VirtualMachineClassReady).d8 k get vm <vm-name> -o json | jq '.status.conditions[] | select(.type | test(".*Ready"))'
- Возможные проблемы:
-
Starting— запуск виртуальной машины.Все зависимые ресурсы ВМ - готовы, и система пытается запустить ВМ на одном из узлов кластера.
- Возможные проблемы:
- Нет подходящего узла для запуска.
- На подходящих узлах недостаточно CPU или памяти.
- Превышены квоты неймспейса или проекта.
-
Диагностика:
- Если запуск затягивается, проверьте
.status.conditions, условиеtype: Running
d8 k get vm <vm-name> -o json | jq '.status.conditions[] | select(.type=="Running")' - Если запуск затягивается, проверьте
- Возможные проблемы:
-
Running— виртуальная машина запущена.ВМ успешно запущена и работает.
- Особенности:
- При установленном в гостевой системе qemu-guest-agent, условие
AgentReadyбудет истинно,а в.status.guestOSInfoбудет отображена информация о запущенной гостевой ОС. - Условие
type: FirmwareUpToDate, status: Falseинформирует о том, что прошивку ВМ требуется обновить. - Условие
type: ConfigurationApplied, status: Falseинформирует о том, что конфигурация ВМ не применена для запущенной ВМ. - Условие
type: SizingPolicyMatched, status: Falseозначает, что конфигурация ресурсов виртуальной машины не соответствует политике сайзинга, заданной в связанном объекте VirtualMachineClass. Чтобы сохранить изменения в конфигурации ВМ, необходимо сначала привести её параметры в соответствие с требованиями этой политики. - Условие
type: AwaitingRestartToApplyConfiguration, status: Trueотображает информацию о необходимости выполнить вручную перезагрузку ВМ, т.к. некоторые изменения конфигурации невозможно применить без перезагрузки ВМ.
- При установленном в гостевой системе qemu-guest-agent, условие
- Возможные проблемы:
- Внутренний сбой в работе ВМ или гипервизора.
-
Диагностика:
- Проверьте
.status.conditions, условиеtype: Running
d8 k get vm <vm-name> -o json | jq '.status.conditions[] | select(.type=="Running")' - Проверьте
- Особенности:
-
Stopping— ВМ останавливается или перезагружается. -
Stopped— ВМ остановлена и не потребляет вычислительные ресурсы. -
Terminating— ВМ удаляется.Данная фаза необратима. Все связанные с ВМ ресурсы освобождаются, но не удаляются автоматически.
-
Migrating— живая миграция ВМ.ВМ переносится на другой узел кластера (живая миграция).
- Особенности:
- Условие
type: Migratableпоказывает, может ли ВМ мигрировать.
- Условие
- Возможные проблемы:
- Несовместимость процессорных инструкций (при использовании типов процессоров host или host-passthrough).
- Различие в версиях ядер на узлах гипервизоров.
- На подходящих узлах недостаточно CPU или памяти.
- Превышены квоты неймспейса или проекта.
- Диагностика:
- Проверьте
.status.conditionsусловиеtype: Migrating, а также блок.status.migrationState
- Проверьте
d8 k get vm <vm-name> -o json | jq '.status | {condition: .conditions[] | select(.type=="Migrating"), migrationState}' - Особенности:
Условие type: SizingPolicyMatched, status: False отображает несоответствие конфигурации ресурсов политике сайзинга используемого VirtualMachineClass. При нарушении политики сохранить параметры ВМ без приведения ресурсов в соответствие политике невозможно.
Условия отображают информацию о состоянии ВМ, а также на возникающие проблемы. Понять, что не так с ВМ можно путем их анализа:
d8 k get vm fedora -o json | jq '.status.conditions[] | select(.message != "")'
Настройки CPU и coreFraction
При создании виртуальной машины вы можете настроить количество процессорных ресурсов которые она будет использовать, с помощью параметров cores и coreFraction.
Параметр cores задает количество виртуальных ядер процессора выделенных для ВМ.
Параметр coreFraction задаёт гарантированную минимальную долю вычислительной мощности, выделяемой на каждое ядро.
Доступные значения coreFraction могут быть определены в ресурсе VirtualMachineClass для заданного диапазона ядер (cores), допускается использовать только эти значения.
Например, если указать cores: 2, для ВМ будет выделено два виртуальных ядра соответствующих двум физическим ядрам гипервизора.
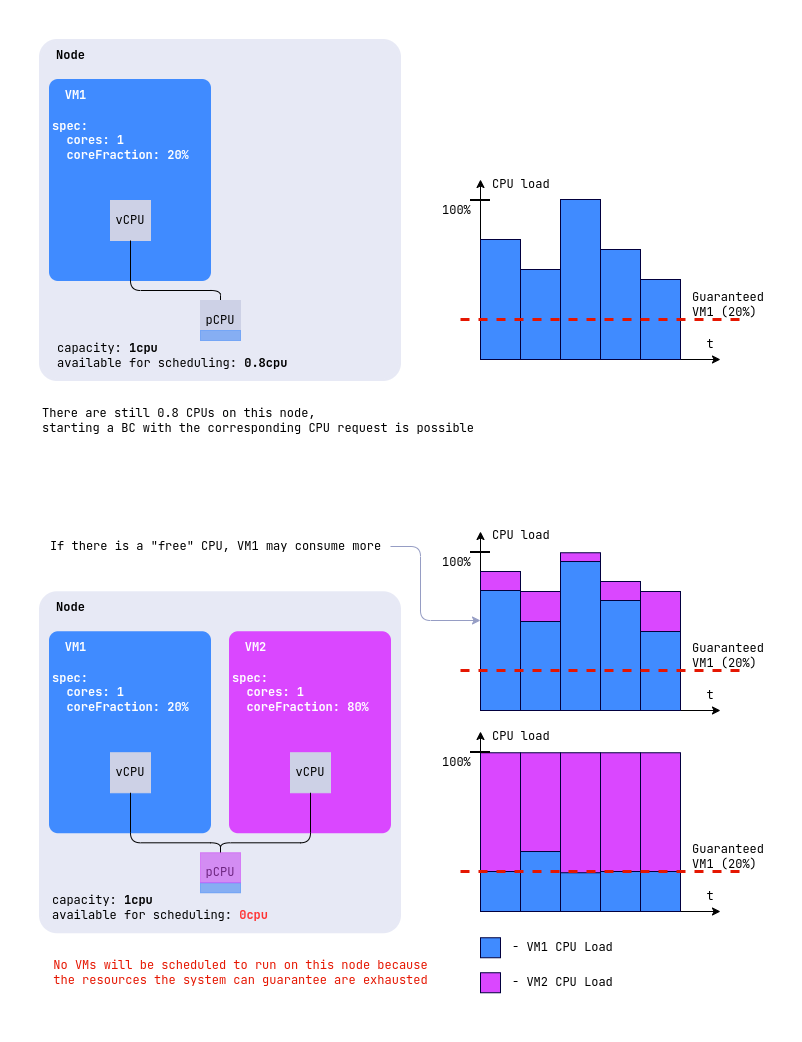
При coreFraction: 20% ВМ гарантировано получит не менее 20% процессорной мощности каждого ядра, независимо от загрузки узла гипервизора. При этом, если на узле есть свободные ресурсы, ВМ может использовать до 100% мощности каждого ядра, что позволяет достичь максимальной производительности.
Таким образом ВМ гарантировано получает 0.2 CPU каждого физического ядра и может задействовать до 100% мощности двух ядер (2 CPU), если на узле есть незадействованные ресурсы.
Если параметр coreFraction не определен, каждому виртуальному ядру ВМ выделяется 100% ядра физического процессора гипервизора.
Пример конфигурации:
spec:
cpu:
cores: 2
coreFraction: 20%
Такой подход позволяет обеспечить стабильную работу ВМ даже при высокой нагрузке в условиях негарантированных выделенных на ВМ процессорных ресурсов (CPU oversubscription), когда виртуальным машинам выделено больше ядер, чем доступно на гипервизоре.
Параметры cores и coreFraction учитываются при планировании размещения ВМ на узлах. Гарантированная мощность (минимальная доля каждого ядра) учитывается при выборе узла, чтобы он мог обеспечить необходимую производительность для всех ВМ. Если узел не располагает достаточными ресурсами для выполнения гарантий, ВМ не будет запущена на этом узле.
Визуализация на примере виртуальных машин со следующими конфигурациями CPU, при размещении их на одном узле:
VM1:
spec:
cpu:
cores: 1
coreFraction: 20%
VM2:
spec:
cpu:
cores: 1
coreFraction: 80%
Настройка ресурсов и политика сайзинга
Политика сайзинга в VirtualMachineClass, заданная в разделе .spec.sizingPolicies, определяет правила настройки ресурсов виртуальных машин, включая количество ядер, объём памяти и долю использования ядер (coreFraction). Эта политика не является обязательной. Если она отсутствует для ВМ, можно указывать произвольные значения для ресурсов без строгих требований. Однако, если политика сайзинга присутствует, конфигурация виртуальной машины должна строго ей соответствовать. В противном случае сохранение конфигурации будет невозможно.
Политика делит количество ядер (cores) на диапазоны, например, 1–4 ядра или 5–8 ядер. Для каждого диапазона указывается, сколько памяти можно выделить (memory) на одно ядро и/или какие значения coreFraction разрешены.
Если конфигурация ВМ (ядра, память или coreFraction) не соответствует политике, в статусе появится условие type: SizingPolicyMatched, status: False.
Если изменить политику в VirtualMachineClass, может потребоваться изменить конфигурацию существующих ВМ в соответствии с новой политикой. Виртуальные машины, не соответствующие условиям новой политики, продолжат работать, но любые изменения их конфигурации нельзя будет сохранить до тех пор, пока они не будут соответствовать новым условиям.
Например:
spec:
sizingPolicies:
- cores:
min: 1
max: 4
memory:
min: 1Gi
max: 8Gi
coreFractions: [5, 10, 20, 50, 100]
- cores:
min: 5
max: 8
memory:
min: 5Gi
max: 16Gi
coreFractions: [20, 50, 100]
Если ВМ использует 2 ядра, она попадает в диапазон 1–4 ядра. В этом случае объём памяти можно выбрать от 1 ГБ до 8 ГБ, а coreFraction — только из значений 5%, 10%, 20%, 50% или 100%. Для 6 ядер — диапазон 5–8 ядер, где объём памяти должен составлять от 5 ГБ до 16 ГБ, а coreFraction — 20%, 50% или 100%.
Помимо сайзинга виртуальных машин, политика также позволяет управлять коэффициентом превышения лимита ресурсов CPU для ВМ.
Например, указав в политике значение coreFraction: 20%, вы гарантируете любой ВМ не менее 20% вычислительных ресурсов процессора, что фактически определит максимально возможное превышение лимита ресурсов CPU в размере 5:1.
Топологии CPU
Топология CPU виртуальной машины (ВМ) определяет, как ядра процессора распределяются по сокетам. Это важно для обеспечения оптимальной производительности и совместимости с приложениями, которые могут зависеть от конфигурации процессора. В конфигурации ВМ вы задаете только общее количество ядер процессора, а топология (количество сокетов и ядер в каждом сокете) рассчитывается автоматически на основе этого значения.
Количество ядер процессора указывается в конфигурации ВМ следующим образом:
spec:
cpu:
cores: 1
Далее система автоматически определяет топологию в зависимости от заданного числа ядер. Правила расчета зависят от диапазона количества ядер и описаны ниже.
- Если количество ядер от 1 до 16 (1 ≤
.spec.cpu.cores≤ 16):- Используется 1 сокет.
- Количество ядер в сокете равно заданному значению.
- Шаг изменения: 1 (можно увеличивать или уменьшать количество ядер по одному).
- Допустимые значения: любое целое число от 1 до 16 включительно.
- Пример: Если задано
.spec.cpu.cores= 8, то топология: 1 сокет с 8 ядрами.
- Если количество ядер от 17 до 32 (16 <
.spec.cpu.cores≤ 32):- Используется 2 сокета.
- Ядра равномерно распределяются между сокетами (количество ядер в каждом сокете одинаковое).
- Шаг изменения: 2 (общее количество ядер должно быть четным).
- Допустимые значения: 18, 20, 22, 24, 26, 28, 30, 32.
- Ограничения: минимум 9 ядер в сокете, максимум 16 ядер в сокете.
- Пример: Если задано
.spec.cpu.cores= 20, то топология: 2 сокета по 10 ядер каждый.
- Если количество ядер от 33 до 64 (32 <
.spec.cpu.cores≤ 64):- Используется 4 сокета.
- Ядра равномерно распределяются между сокетами.
- Шаг изменения: 4 (общее количество ядер должно быть кратно 4).
- Допустимые значения: 36, 40, 44, 48, 52, 56, 60, 64.
- Ограничения: минимум 9 ядер в сокете, максимум 16 ядер в сокете.
- Пример: Если задано
.spec.cpu.cores= 40, то топология: 4 сокета по 10 ядер каждый.
- Если количество ядер больше 64 (
.spec.cpu.cores> 64):- Используется 8 сокетов.
- Ядра равномерно распределяются между сокетами.
- Шаг изменения: 8 (общее количество ядер должно быть кратно 8).
- Допустимые значения: 72, 80, 88, 96 и так далее до 248.
- Ограничения: минимум 9 ядер в сокете.
- Пример: Если задано
.spec.cpu.cores= 80, то топология: 8 сокетов по 10 ядер каждый.
Шаг изменения указывает, на сколько можно увеличивать или уменьшать общее количество ядер, чтобы они равномерно распределялись по сокетам.
Максимально возможное количество ядер — 248.
Сводная таблица по диапазону spec.cpu.cores:
| Диапазон ядер | Число сокетов | Кратность | Минимум ядер в сокете | Максимум ядер в сокете |
|---|---|---|---|---|
1 ≤ cores ≤ 16 |
1 | 1 | 1 | 16 |
16 < cores ≤ 32 |
2 | 2 | 9 | 16 |
32 < cores ≤ 64 |
4 | 4 | 9 | 16 |
64 < cores ≤ 248 |
8 | 8 | 9 | 16 |
Overhead памяти не зависит от максимально возможной топологии по числу vCPU и вычисляется по фактически активным ядрам: (число сокетов × ядер на сокет × число потоков на ядро) × 8 MiB на каждое логическое ядро.
Пример: при spec.cpu.cores: 20 в статусе отображается топология из двух сокетов по 10 ядер:
spec:
cpu:
cores: 20
# ...
status:
resources:
cpu:
topology:
coresPerSocket: 10
sockets: 2
Текущая топология ВМ (количество сокетов и ядер в каждом сокете) отображается в статусе ВМ в следующем формате:
status:
resources:
cpu:
coreFraction: 10%
cores: 1
requestedCores: "1"
runtimeOverhead: "0"
topology:
sockets: 1
coresPerSocket: 1
Настройка типа ОС и загрузчика
Параметр osType определяет тип операционной системы и применяет оптимальный набор виртуальных устройств и параметров для корректной работы ВМ.
Поддерживаемые значения:
Generic(по умолчанию) — для Linux и других операционных систем. Используется стандартная конфигурация виртуальных устройств.Windows— для операционных систем семейства Microsoft Windows. Автоматически включает функции Hyper-V, TPM-устройство и другие настройки, оптимизированные для работы Windows.
TPM-устройство, предоставляемое виртуальной машине, не является постоянным (эмуляция TPM в памяти). При перезагрузке или миграции ВМ состояние TPM сбрасывается. Учитывайте это ограничение при использовании функций безопасности Windows, зависящих от TPM.
Параметр bootloader определяет тип загрузчика виртуальной машины:
BIOS(по умолчанию) — использование устаревшего BIOS;EFI— использование Unified Extensible Firmware Interface (UEFI/EFI);EFIWithSecureBoot— использование UEFI/EFI с поддержкой Secure Boot.
Пример конфигурации для виртуальной машины с Windows:
spec:
osType: Windows
bootloader: EFI
# остальные параметры...
Пример конфигурации для виртуальной машины с Linux (значения по умолчанию можно не указывать):
spec:
osType: Generic
bootloader: BIOS
# остальные параметры...
Для большинства современных Linux-дистрибутивов рекомендуется использовать bootloader: EFI. Для Windows обычно используют bootloader: EFI или bootloader: EFIWithSecureBoot.
Параметр enableParavirtualization управляет использованием шины virtio для подключения виртуальных устройств ВМ:
true(по умолчанию) — используется шинаvirtioдля дисков, сетевых интерфейсов и других устройств, что обеспечивает лучшую производительность.false— используется эмуляция стандартных устройств (SATA для дисков, e1000e для сетевых интерфейсов), что может быть необходимо для совместимости со старыми ОС.
Для использования режима паравиртуализации (virtio) в некоторых операционных системах требуется установка соответствующих драйверов. Если драйверы не установлены, ВМ может не загрузиться или устройства могут работать некорректно.
Пример конфигурации с отключенной паравиртуализацией:
spec:
enableParavirtualization: false
# остальные параметры...
Сценарии начальной инициализации ВМ
Сценарии начальной инициализации предназначены для первичной конфигурации виртуальной машины при её запуске.
В качестве сценариев начальной инициализации поддерживаются:
Cloud-Init
Cloud-Init — это инструмент для автоматической настройки виртуальных машин при первом запуске. Он позволяет выполнять широкий спектр задач конфигурации без ручного вмешательства.
Конфигурация Cloud-Init записывается в формате YAML и должна начинаться с заголовка #cloud-config в начале блока конфигурации. О других возможных заголовках и их назначении вы можете узнать в официальной документации по cloud-init.
Основные возможности Cloud-Init:
- создание пользователей, установка паролей, добавление SSH-ключей для доступа;
- автоматическая установка необходимого программного обеспечения при первом запуске;
- запуск произвольных команд и скриптов для настройки системы;
- автоматический запуск и включение системных сервисов (например,
qemu-guest-agent).
Типичные сценарии использования
-
Добавление SSH-ключа для предустановленного пользователя, который уже может присутствовать в cloud-образе (например, пользователь
ubuntuв официальных образах Ubuntu). Имя такого пользователя зависит от образа. Уточните его в документации к вашему дистрибутиву.#cloud-config ssh_authorized_keys: - ssh-ed25519 AAAAB3NzaC1yc2EAAAADAQABAAABAQD... your-public-key ... -
Создание пользователя с паролем и SSH-ключом:
#cloud-config users: - name: cloud passwd: "$6$rounds=4096$saltsalt$..." lock_passwd: false sudo: ALL=(ALL) NOPASSWD:ALL shell: /bin/bash ssh-authorized-keys: - ssh-ed25519 AAAAB3NzaC1yc2EAAAADAQABAAABAQD... your-public-key ... ssh_pwauth: TrueДля генерации хеша пароля используйте команду
mkpasswd --method=SHA-512 --rounds=4096. -
Установка пакетов и сервисов:
#cloud-config package_update: true packages: - nginx - qemu-guest-agent runcmd: - systemctl daemon-reload - systemctl enable --now nginx.service - systemctl enable --now qemu-guest-agent.service
Использование Cloud-Init
Сценарий Cloud-Init можно встраивать непосредственно в спецификацию виртуальной машины, но этот сценарий ограничен максимальной длиной в 2048 байт:
spec:
provisioning:
type: UserData
userData: |
#cloud-config
package_update: true
...
При более длинных сценариях и/или наличии приватных данных, сценарий начальной инициализации виртуальной машины может быть создан в ресурсе Secret. Пример ресурса Secret со сценарием Cloud-Init приведен ниже:
apiVersion: v1
kind: Secret
metadata:
name: cloud-init-example
data:
userData: <base64 data>
type: provisioning.virtualization.deckhouse.io/cloud-init
Фрагмент конфигурации виртуальной машины при использовании скрипта начальной инициализации Cloud-Init, хранящегося в ресурсе Secret:
spec:
provisioning:
type: UserDataRef
userDataRef:
kind: Secret
name: cloud-init-example
Значение поля .data.userData должно быть закодировано в формате Base64. Для кодирования можно использовать команду base64 -w 0 или echo -n "content" | base64.
Sysprep
Для конфигурирования виртуальных машин под управлением ОС Windows с использованием Sysprep поддерживается только вариант с ресурсом Secret.
Пример ресурса Secret со сценарием Sysprep:
apiVersion: v1
kind: Secret
metadata:
name: sysprep-example
data:
unattend.xml: <base64 data>
type: provisioning.virtualization.deckhouse.io/sysprep
Значение поля .data.unattend.xml должно быть закодировано в формате Base64. Для кодирования можно использовать команду base64 -w 0 или echo -n "content" | base64.
Фрагмент конфигурации виртуальной машины с использованием скрипта начальной инициализации Sysprep в ресурсе Secret:
spec:
provisioning:
type: SysprepRef
sysprepRef:
kind: Secret
name: sysprep-example
Агент гостевой ОС
Для повышения эффективности управления ВМ рекомендуется установить QEMU Guest Agent — инструмент, который обеспечивает взаимодействие между гипервизором и операционной системой внутри ВМ.
Чем поможет агент?
- Обеспечит создание консистентных снимков дисков и ВМ.
-
Позволит получать информацию о работающей ОС, которая будет отражена в статусе ВМ. Пример:
status: guestOSInfo: id: fedora kernelRelease: 6.11.4-301.fc41.x86_64 kernelVersion: "#1 SMP PREEMPT_DYNAMIC Sun Oct 20 15:02:33 UTC 2024" machine: x86_64 name: Fedora Linux prettyName: Fedora Linux 41 (Cloud Edition) version: 41 (Cloud Edition) versionId: "41" -
Позволит отслеживать, что ОС действительно загрузилась:
d8 k get vm -o wideПример вывода (колонка
AGENT):NAME PHASE CORES COREFRACTION MEMORY NEED RESTART AGENT MIGRATABLE NODE IPADDRESS AGE fedora Running 6 5% 8000Mi False True True virtlab-pt-1 10.66.10.1 5d21h
Как установить QEMU Guest Agent:
Для Debian-based ОС:
sudo apt install qemu-guest-agent
Для Centos-based ОС:
sudo yum install qemu-guest-agent
Запуск службы агента:
sudo systemctl enable --now qemu-guest-agent
Установку агента для Linux ОС можно автоматизировать с помощью сценария первичной инициализации cloud-init. Ниже приведён пример фрагмента такого сценария для установки qemu-guest-agent:
#cloud-config
package_update: true
packages:
- qemu-guest-agent
runcmd:
- systemctl enable --now qemu-guest-agent.service
QEMU Guest Agent не требует дополнительной настройки после установки. Однако для обеспечения консистентности снимков на уровне приложений (без остановки сервисов) можно добавить скрипты, которые будут автоматически выполняться в гостевой ОС до и после операций заморозки (freeze) и оттаивания (thaw) файловой системы. Скрипты должны иметь права на выполнение и размещаться в специальном каталоге, путь к которому зависит от используемого дистрибутива:
/etc/qemu-ga/hooks.d/— для дистрибутивов на базе Debian/Ubuntu;/etc/qemu/fsfreeze-hook.d/— для дистрибутивов на базе RHEL/CentOS/Fedora.
Подключение к виртуальной машине
Для подключения к виртуальной машине доступны следующие способы:
- протокол удаленного управления (например SSH), который должен быть предварительно настроен на виртуальной машине;
- серийная консоль (serial console);
- протокол VNC.
Пример подключения к виртуальной машине с использованием серийной консоли:
d8 v console linux-vm
Пример вывода:
Successfully connected to linux-vm console. The escape sequence is ^]
linux-vm login: cloud
Password: cloud
Нажмите Ctrl+] для завершения работы с серийной консолью.
Серийная консоль не поддерживает автоматическое изменение размера терминала. Если вывод полноэкранных приложений или текстовых редакторов отображается некорректно, выполните после входа в систему команду:
stty rows <число_строк> cols <число_столбцов>
Например: stty rows 50 cols 200
Если в системе установлен пакет xterm, можно также использовать команду resize.
Пример команды для подключения по VNC:
d8 v vnc linux-vm
Пример команды для подключения по SSH:
d8 v ssh cloud@linux-vm --local-ssh
Как подключиться к виртуальной машине в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация» → «Виртуальные машины».
- Из списка выберите необходимую ВМ и нажмите на её имя.
- В открывшейся форме перейдите на вкладку «TTY» для работы с серийной консолью.
- В открывшейся форме перейдите на вкладку «VNC» для подключения по VNC.
- Перейдите в открывшееся окно. Здесь можно подключиться к ВМ.
Политика запуска и управление состоянием ВМ
Политика запуска виртуальной машины предназначена для автоматизированного управления состоянием виртуальной машины. Определяется она в виде параметра .spec.runPolicy в спецификации виртуальной машины. Поддерживаются следующие политики:
AlwaysOnUnlessStoppedManually(по умолчанию) — после создания ВМ всегда находится в запущенном состоянии. В случае сбоев работа ВМ восстанавливается автоматически. Остановка ВМ возможно только путем вызова командыd8 v stopили создания соответствующей операции.AlwaysOn— после создания ВМ всегда находится в работающем состоянии, даже в случае ее выключения средствами ОС. В случае сбоев работа ВМ восстанавливается автоматически.Manual— после создания состоянием ВМ управляет пользователь вручную с использованием команд или операций. ВМ сразу после создания находится в выключенном состоянии. Для включения необходимо выполнить командуd8 v start.AlwaysOff— после создания ВМ всегда находится в выключенном состоянии. Возможность включения ВМ через команды\операции - отсутствует.
Как выбрать политику запуска ВМ в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация» → «Виртуальные машины».
- Из списка выберите необходимую ВМ и нажмите на её имя.
- На вкладке «Конфигурация» прокрутите страницу вниз до раздела «Дополнительные параметры».
- Выберите нужную политику в переключателе «Политика запуска».
Состоянием виртуальной машины можно управлять с помощью следующих методов:
- Создание ресурса
VirtualMachineOperation(vmop). - Использование утилиты
d8с соответствующей подкомандой.
Ресурс VirtualMachineOperation декларативно определяет императивное действие, которое должно быть выполнено на виртуальной машине. Это действие применяется к виртуальной машине сразу после создания соответствующего vmop. Действие применяется к виртуальной машине один раз.
Пример операции для выполнения перезагрузки виртуальной машины с именем linux-vm:
d8 k create -f - <<EOF
apiVersion: virtualization.deckhouse.io/v1alpha2
kind: VirtualMachineOperation
metadata:
generateName: restart-linux-vm-
spec:
virtualMachineName: linux-vm
# Тип применяемой операции = применяемая операция.
type: Restart
EOF
Посмотреть результат действия можно с использованием команды:
d8 k get virtualmachineoperation
# или
d8 k get vmop
Аналогичное действие можно выполнить с использованием утилиты d8:
d8 v restart linux-vm
Перечень возможных операций приведен в таблице ниже:
| d8 | vmop type | Действие |
|---|---|---|
d8 v stop |
Stop |
Остановить ВМ |
d8 v start |
Start |
Запустить ВМ |
d8 v restart |
Restart |
Перезапустить ВМ |
d8 v evict |
Evict |
Мигрировать ВМ на другой узел |
Как выполнить операцию в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация» → «Виртуальные машины».
- Из списка выберите нужную виртуальную машину и нажмите кнопку с многоточием.
- Во всплывающем меню можете выбрать возможные операции для ВМ.
Изменение конфигурации ВМ
Конфигурацию виртуальной машины можно изменять в любое время после создания ресурса VirtualMachine. Однако то, как эти изменения будут применены, зависит от текущей фазы виртуальной машины и характера внесённых изменений.
Изменения в конфигурацию виртуальной машины можно внести с использованием следующей команды:
d8 k edit vm linux-vm
Если виртуальная машина находится в выключенном состоянии (.status.phase: Stopped), внесённые изменения вступят в силу сразу после её запуска.
Если виртуальная машина работает (.status.phase: Running), то способ применения изменений зависит от их типа:
| Блок конфигурации | Как применяется |
|---|---|
.metadata.labels |
Сразу и распространяется на под ВМ |
.metadata.annotations |
Сразу и распространяется на под ВМ |
.spec.liveMigrationPolicy |
Сразу |
.spec.runPolicy |
Сразу |
.spec.disruptions.restartApprovalMode |
Сразу |
.spec.affinity |
EE, SE+ : Сразу, CE: Требуется перезапуск ВМ |
.spec.nodeSelector |
EE, SE+ : Сразу, CE: Требуется перезапуск ВМ |
.spec.cpu.cores |
Может применяться сразу при включённом hotplug (EE, SE+), см. раздел «Горячее подключение CPU»; иначе требуется перезапуск ВМ |
.spec.* |
Требуется перезапуск ВМ |
Как изменить конфигурацию ВМ в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация» → «Виртуальные машины».
- Из списка выберите необходимую ВМ и нажмите на её имя.
- Вы находитесь на вкладке «Конфигурация», где можете вносить изменения.
- Список измененных параметров и предупреждение, если необходимо перезапустить ВМ, отображаются вверху страницы.
Рассмотрим пример изменения конфигурации виртуальной машины:
Предположим, мы хотим изменить количество ядер процессора. В данный момент виртуальная машина запущена и использует одно ядро, что можно подтвердить, подключившись к ней через серийную консоль и выполнив команду nproc.
d8 v ssh cloud@linux-vm --local-ssh --command "nproc"
Пример вывода:
1
Примените следующий патч к виртуальной машине, чтобы изменить количество ядер с 1 на 2.
d8 k patch vm linux-vm --type merge -p '{"spec":{"cpu":{"cores":2}}}'
# Или внесите аналогичные изменения, отредактировав ресурс.
d8 k edit vm linux-vm
Пример вывода:
# virtualmachine.virtualization.deckhouse.io/linux-vm patched
Изменения в конфигурации внесены, но ещё не применены к виртуальной машине. Проверьте это, повторно выполнив:
d8 v ssh cloud@linux-vm --local-ssh --command "nproc"
Пример вывода:
1
Для применения этого изменения необходим перезапуск виртуальной машины. Выполните следующую команду, чтобы увидеть изменения, ожидающие применения (требующие перезапуска):
d8 k get vm linux-vm -o jsonpath="{.status.restartAwaitingChanges}" | jq .
Пример вывода:
[
{
"currentValue": 1,
"desiredValue": 2,
"operation": "replace",
"path": "cpu.cores"
}
]
Выполните команду:
d8 k get vm linux-vm -o wide
Пример вывода:
NAME PHASE CORES COREFRACTION MEMORY NEED RESTART AGENT MIGRATABLE NODE IPADDRESS AGE
linux-vm Running 2 100% 1Gi True True True virtlab-pt-1 10.66.10.13 5m16s
В колонке NEED RESTART мы видим значение True, а это значит что для применения изменений требуется перезагрузка.
Выполните перезагрузку виртуальной машины:
d8 v restart linux-vm
После перезагрузки изменения будут применены и блок .status.restartAwaitingChanges будет пустой.
Выполните команду для проверки:
d8 v ssh cloud@linux-vm --local-ssh --command "nproc"
Пример вывода:
2
Порядок применения изменений виртуальной машины через «ручной» рестарт является поведением по умолчанию. Если есть необходимость применять внесенные изменения сразу и автоматически, для этого нужно изменить политику применения изменений:
spec:
disruptions:
restartApprovalMode: Automatic
Как выполнить операцию в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация» → «Виртуальные машины».
- Из списка выберите необходимую ВМ и нажмите на её имя.
- На вкладке «Конфигурация» прокрутите страницу вниз до раздела «Дополнительные параметры».
- Включите переключатель «Автоприменение изменений».
- Нажмите на появившуюся кнопку «Сохранить».
Горячее подключение CPU
Горячее подключение CPU позволяет изменять количество ядер (spec.cpu.cores) у работающей ВМ без перезагрузки, если изменение можно применить через живую миграцию. В пределах текущей топологии CPU можно как увеличивать, так и уменьшать число ядер.
По умолчанию эта функциональность отключена. Чтобы включить, добавьте HotplugCPUWithLiveMigration в массив .spec.settings.featureGates в ModuleConfig/virtualization:
kind: ModuleConfig
metadata:
name: virtualization
spec:
settings:
featureGates:
- HotplugCPUWithLiveMigration
Если новое значение spec.cpu.cores попадает в диапазон горячего подключения для текущей топологии и ВМ допускает миграцию, изменение применяется через живую миграцию. Если новому значению требуется другая топология CPU или ВМ не может быть мигрирована, потребуется перезагрузка ВМ. Необходимость перезагрузки отражается в статусе ВМ в колонке NEED RESTART.
Правила расчёта топологии и допустимые шаги изменения spec.cpu.cores описаны в разделе Топологии CPU.
Особенности гостевых ОС:
- После живой миграции новые vCPU могут потребовать явной активации в гостевой ОС.
-
В Linux добавленные CPU можно включить через sysfs:
echo 1 > /sys/devices/system/cpu/cpu1/online -
Чтобы в Linux автоматически включать новые CPU, настройте правило
udev. После этого добавленные CPU отображаются в выводеcat /proc/cpuinfoи вtop:cat <<'EOF' > /etc/udev/rules.d/99-hotplug-cpu.rules SUBSYSTEM=="cpu",ACTION=="add",RUN+="/bin/sh -c '[ ! -e /sys$devpath/online ] || echo 1 > /sys$devpath/online'" EOF
Ограничения:
- Изменение
spec.cpu.coresбез перезагрузки возможно только в пределах диапазона горячего подключения текущей топологии CPU. - Если изменение требует смены топологии CPU, необходима перезагрузка ВМ.
- При уменьшении количества CPU в пределах текущей топологии распределение ядер по сокетам может стать неравномерным.
Горячее подключение памяти
Горячее подключение памяти позволяет увеличивать объём памяти (spec.memory.size) у работающей ВМ без перезагрузки, если изменение можно применить через живую миграцию. Уменьшение размера памяти всегда требует перезагрузки ВМ.
По умолчанию эта функциональность отключена. Чтобы включить, добавьте HotplugMemoryWithLiveMigration в массив .spec.settings.featureGates в ModuleConfig virtualization:
kind: ModuleConfig
metadata:
name: virtualization
spec:
settings:
featureGates:
- HotplugMemoryWithLiveMigration
Если новое значение spec.memory.size больше текущего и ВМ допускает миграцию, изменение применяется через живую миграцию. Если требуется уменьшить память, изначально заданный размер памяти меньше 1 ГБ или ВМ не может быть мигрирована, потребуется перезагрузка ВМ. Необходимость перезагрузки отражается в статусе ВМ в колонке NEED RESTART.
Особенности гостевых ОС:
- После живой миграции при увеличении памяти новые блоки памяти могут потребовать явной активации в гостевой ОС; память, заданная при создании ВМ, дополнительной активации не требует.
-
В Linux добавленную память можно включить через sysfs (имя устройства см. в выводе
ls /sys/bus/memory/devices/):echo 1 > /sys/bus/memory/devices/memoryXXX/online -
Чтобы в Linux автоматически включать добавленную память, настройте правило
udev. После этого добавленная память отображается в выводеfreeиlsmem:cat <<'EOF' > /etc/udev/rules.d/99-hotplug-memory.rules SUBSYSTEM=="memory",ACTION=="add",DEVPATH=="/devices/system/memory/memory[0-9]*", TEST=="state", ATTR{state}!="online", ATTR{state}="online" EOF
Ограничения:
- Увеличение памяти без перезагрузки возможно только если размер памяти ВМ не меньше 1 ГБ. Если изначально задано меньше 1 ГБ, любое изменение размера потребует перезагрузки.
- Максимальный размер памяти для ВМ в текущей версии модуля ограничен значением 256 ГБ.
Размещение ВМ по узлам
Для управления размещением виртуальных машин (параметров размещения) по узлам можно использовать следующие подходы:
- Простое связывание по лейблам (
nodeSelector) — базовый способ выбора узлов с заданными лейблами. - Предпочтительное связывание (
Affinity):nodeAffinity— определяет приоритетные узлы для размещения.virtualMachineAndPodAffinity— обеспечивает совместное размещение ВМ и контейнеров.
- Избежание совместного размещения (
AntiAffinity):virtualMachineAndPodAntiAffinity— предотвращает размещение ВМ и контейнеров на одном узле.
Все указанные параметры (включая параметр .spec.nodeSelector из VirtualMachineClass) применяются комплексно при планировании ВМ. Если хотя бы одно условие не может быть выполнено, запуск ВМ не будет выполнен. Для минимизации рисков рекомендуется:
- Создавать непротиворечивые правила размещения.
- Проверять совместимость правил до их применения.
- Учитывать типы условий:
- Жесткие (
requiredDuringSchedulingIgnoredDuringExecution) — требуют строгого соблюдения. - Мягкие (
preferredDuringSchedulingIgnoredDuringExecution) — допускают частичное выполнение.
- Жесткие (
- Используйте комбинации лейблов вместо одиночных ограничений. Например, вместо required для одного лейбла (например, env=prod) используйте несколько preferred условий.
- Учитывайте порядок запуска взаимозависимых ВМ. При использовании Affinity между ВМ (например, бэкенд зависит от базы данных) запускайте сначала ВМ, на которые ссылаются правила, чтобы избежать блокировок.
- Планируйте резервные узлы для критических нагрузок. Для ВМ с жесткими требованиями (например, AntiAffinity) предусмотрите дополнительные узлы, чтобы избежать простоев при сбое или выводе узла в режим обслуживания.
- Учитывайте существующие ограничения (
taints) на узлах. При необходимости можно добавить соответствующиеtolerationsдля ВМ.
При изменении параметров размещения:
- Если текущее расположение ВМ соответствует новым требованиям, она остается на текущем узле.
-
Если требования нарушаются:
- В платных редакциях: ВМ автоматически перемещается на подходящий узел с помощью живой миграции.
- В CE-редакции: для применения ВМ будет требоваться перезагрузка.
Как управлять параметрами размещения ВМ по узлам в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация» → «Виртуальные машины».
- Из списка выберите необходимую ВМ и нажмите на её имя.
- На вкладке «Конфигурация» прокрутите страницу до раздела «Размещение».
Толерантность к ограничениям узлов
Tolerations позволяют ВМ запускаться на узлах с ограничениями (taints), которые иначе блокируют планирование (scheduling). Это полезно, когда нужно запускать ВМ на специальных узлах (например, тестовых) или узлах с определёнными характеристиками.
Пример использования tolerations для разрешения запуска на узлах с taint node.deckhouse.io/group=:NoSchedule:
spec:
tolerations:
- key: "node.deckhouse.io/group"
operator: "Exists"
effect: "NoSchedule"
Каждый элемент списка tolerations должен соответствовать taint на узле, чтобы ВМ могла быть размещена на этом узле.
Для просмотра информации об узлах кластера (включая taints) требуется роль пользователя с правами доступа к ресурсам уровня кластера.
Чтобы посмотреть taints на узлах кластера, выполните команду:
d8 k get nodes -o custom-columns=NAME:.metadata.name,TAINTS:.spec.taints
Для более подробной информации:
d8 k describe node <node-name>
Простое связывание по лейблам (nodeSelector)
nodeSelector — это простейший способ контролировать размещение виртуальных машин, используя набор лейблов. Он позволяет задать, на каких узлах могут запускаться виртуальные машины, выбирая узлы с необходимыми лейблами.
spec:
nodeSelector:
disktype: ssd
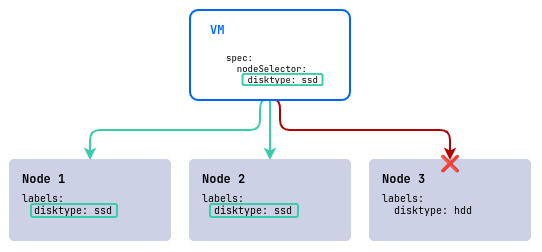
В этом примере в кластере три узла: два с быстрыми дисками (disktype=ssd) и один с медленными (disktype=hdd). Виртуальная машина будет размещена только на узлах, которые имеют лейбл disktype со значением ssd.
Как выполнить операцию в веб-интерфейсе в разделе «Размещение»:
- Нажмите «Добавить» в блоке «Запустить по узлам» → «Выберите узлы по лейблам».
- Во всплывающем окне можете задать «Ключ», «Значение» ключа, что соответствует настройкам
spec.nodeSelector. - Для подтверждения параметров ключа нажмите кнопку «Enter».
- Нажмите на появившуюся кнопку «Сохранить».
Предпочтительное связывание (Affinity)
Affinity предоставляет более гибкие и мощные инструменты по сравнению с nodeSelector. Он позволяет задавать «предпочтения» и «обязательности» для размещения виртуальных машин. Affinity поддерживает два вида: nodeAffinity и virtualMachineAndPodAffinity.
Требования к размещению могут быть:
- Жёсткие (
requiredDuringSchedulingIgnoredDuringExecution) — ВМ размещается только на узлах, удовлетворяющих условию. - Мягкие (
preferredDuringSchedulingIgnoredDuringExecution) — ВМ размещается на подходящих узлах, если это возможно.
nodeAffinity — определяет узлы для запуска ВМ с помощью выражений селекторов лейблов.
Пример использования nodeAffinity с жестким правилом:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
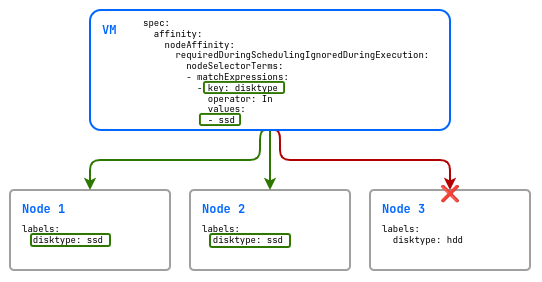
В этом примере в кластере три узла: два с быстрыми дисками (disktype=ssd) и один с медленными (disktype=hdd). Виртуальная машина будет размещена только на узлах, которые имеют лейбл disktype со значением ssd.
Если использовать мягкое требование (preferredDuringSchedulingIgnoredDuringExecution), то при отсутствии ресурсов для запуска ВМ на узлах с дисками disktype=ssd она будет запланирована на узле с дисками disktype=hdd.
virtualMachineAndPodAffinity управляет размещением виртуальных машин относительно других виртуальных машин. Он позволяет задавать предпочтение размещения виртуальных машин на тех же узлах, где уже запущены определенные виртуальные машины.
Пример мягкого правила:
spec:
affinity:
virtualMachineAndPodAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
podAffinityTerm:
labelSelector:
matchLabels:
server: database
topologyKey: "kubernetes.io/hostname"
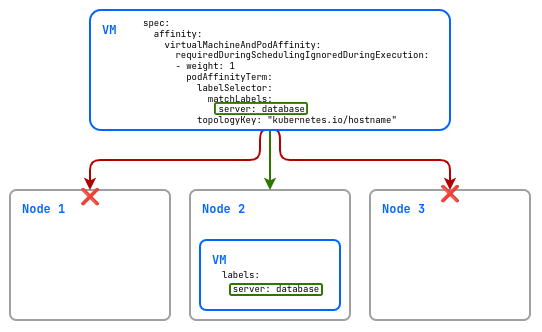
В этом примере виртуальная машина будет размещена, если будет такая возможность (так как используется preferred) только на узлах на которых присутствует виртуальная машина с лейблом server и значением database.
Чтобы размещать ВМ по зонам доступности (а не привязывать к конкретным узлам), задайте topologyKey: topology.kubernetes.io/zone (см. раздел «Размещение ВМ по зонам доступности»).
Как задавать «предпочтения» и «обязательности» для размещения виртуальных машин в веб-интерфейсе в разделе «Размещение»:
- Нажмите «Добавить» в блоке «Запустить ВМ рядом с другими ВМ».
- Во всплывающем окне можете задать «Ключ», «Значение» ключа, что соответствует настройкам
spec.affinity.virtualMachineAndPodAffinity. - Для подтверждения параметров ключа нажмите кнопку «Enter».
- Выберите одну из опций
На одном сервереилиВ одной зоне, что соответствует параметруtopologyKey. - Нажмите на появившуюся кнопку «Сохранить».
Избежание совместного размещения (AntiAffinity)
AntiAffinity используется для предотвращения совместного размещения ВМ на узлах. Полезно для обеспечения отказоустойчивости или балансировки нагрузки.
Требования к размещению могут быть:
- Жёсткие (
requiredDuringSchedulingIgnoredDuringExecution) — ВМ размещается только на узлах, удовлетворяющих условию. - Мягкие (
preferredDuringSchedulingIgnoredDuringExecution) — ВМ размещается на подходящих узлах, если это возможно.
Будьте осторожны при использовании жестких требований в небольших кластерах, где мало узлов для запуска виртуальных машин (ВМ). Если используется параметр virtualMachineAndPodAntiAffinity с типом requiredDuringSchedulingIgnoredDuringExecution для виртуальных машин, это означает, что каждая копия ВМ должна размещаться на отдельном узле. В условиях ограниченного количества узлов в кластере это может привести к ситуации, когда некоторые ВМ не смогут быть запущены из-за недостатка доступных узлов.
Термины Affinity и AntiAffinity применимы только к отношению между виртуальными машинами. Для узлов используемые привязки называются nodeAffinity. В nodeAffinity нет отдельного антитеза, как в случае с virtualMachineAndPodAffinity, но можно создать противоположные условия, задав отрицательные операторы в выражениях лейблов: чтобы акцентировать внимание на исключении определенных узлов, можно воспользоваться nodeAffinity с оператором, таким как NotIn.
Пример использования virtualMachineAndPodAntiAffinity:
spec:
affinity:
virtualMachineAndPodAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
server: database
topologyKey: "kubernetes.io/hostname"
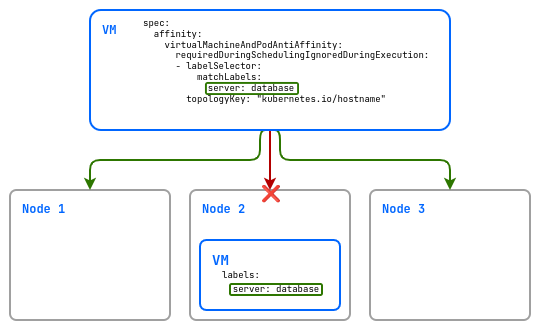
В данном примере создаваемая виртуальная машина не будет размещена на одном узле с виртуальной машиной с лейблом server: database.
Чтобы размещать ВМ по зонам доступности (а не привязывать к конкретным узлам), задайте topologyKey: topology.kubernetes.io/zone (см. раздел «Размещение ВМ по зонам доступности»).
Как настроить предотвращение совместного размещения ВМ на узлах в веб-интерфейсе в разделе «Размещение»:
- Нажмите «Добавить» в блоке «Определять схожие ВМ по лейблам» → «Выберите лейблы».
- Во всплывающем окне можете задать «Ключ», «Значение» ключа, что соответствует настройкам
spec.affinity.virtualMachineAndPodAntiAffinity. - Для подтверждения параметров ключа нажмите кнопку «Enter».
- Установите галочку рядом с теми лейблами, которые хотите использовать в настройке размещения.
- Выберите одну из опций в разделе «Выберите опции».
- Нажмите на появившуюся кнопку «Сохранить».
Размещение ВМ по зонам доступности
Зоны доступности должны быть предварительно настроены на узлах кластера. Для этого на узлах должна быть установлен лейбл topology.kubernetes.io/zone с указанием зоны доступности.
В примерах выше используется topologyKey: "kubernetes.io/hostname", что размещает ВМ на одном узле. Для размещения ВМ по зонам доступности вместо узлов используйте topologyKey: "topology.kubernetes.io/zone".
При использовании Affinity с topologyKey: "topology.kubernetes.io/zone" ВМ будут размещаться в той же зоне доступности, где присутствует виртуальная машина с указанными лейблами.
При использовании AntiAffinity с topologyKey: "topology.kubernetes.io/zone" ВМ не будут размещаться в той же зоне доступности, что и виртуальная машина с указанными лейблами. Это полезно для обеспечения отказоустойчивости при распределении ВМ по разным зонам доступности.
Чтобы посмотреть зоны доступности на узлах кластера (если эти зоны заданы), выполните команду:
d8 k get nodes -o custom-columns=NAME:.metadata.name,ZONE:.metadata.labels.topology\.kubernetes\.io/zone
Подключение блочных устройств (диски и образы)
Блочные устройства можно разделить на два типа по способу их подключения: статические и динамические (hotplug).
Блочные устройства и их особенности представлены в таблице:
| Тип блочного устройства | Комментарий |
|---|---|
VirtualImage |
подключается в режиме для чтения, или как cdrom для iso-образов |
ClusterVirtualImage |
подключается в режиме для чтения, или как cdrom для iso-образов |
VirtualDisk |
подключается в режиме для чтения и записи |
Загрузочные блочные устройства
Загрузочные блочные устройства указываются в спецификации виртуальной машины в блоке .spec.blockDeviceRefs в виде списка. Порядок устройств в этом списке определяет последовательность их загрузки. Таким образом, если диск или образ указан первым, загрузчик сначала попробует загрузиться с него. Если это не удастся, система перейдет к следующему устройству в списке и попытается загрузиться с него. И так далее до момента обнаружения первого загрузчика.
Изменение состава и порядка устройств в блоке .spec.blockDeviceRefs возможно только с перезагрузкой виртуальной машины.
Фрагмент конфигурации VirtualMachine со статически подключенными диском и проектным образом:
spec:
blockDeviceRefs:
- kind: VirtualDisk
name: <virtual-disk-name>
- kind: VirtualImage
name: <virtual-image-name>
Как работать с загрузочными блочными устройствами в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация» → «Виртуальные машины».
- Из списка выберите необходимую ВМ и нажмите на её имя.
- На вкладке «Конфигурация» прокрутите страницу до раздела «Диски и образы».
- В секции «Загрузочные диски» доступны следующие действия:
Добавить— подключить к ВМ новый диск или образ;Извлечь— отключить устройство от ВМ (образ или диск остаётся в проекте, его можно снова подключить к этой или другой ВМ);Удалить— удалить сам ресурс образа или диска из кластера (после удаления его нельзя использовать повторно);Изменить размер— изменить размер диска;Изменить порядок— изменить порядок загрузки с устройств.
Дополнительные блочные устройства
Дополнительные блочные устройства можно подключать и отключать от работающей виртуальной машины без необходимости её перезагрузки.
Для подключения дополнительных блочных устройств используется ресурс VirtualMachineBlockDeviceAttachment (vmbda).
Создайте ресурс, который подключит пустой диск blank-disk к виртуальной машине linux-vm:
d8 k apply -f - <<EOF
apiVersion: virtualization.deckhouse.io/v1alpha2
kind: VirtualMachineBlockDeviceAttachment
metadata:
name: attach-blank-disk
spec:
blockDeviceRef:
kind: VirtualDisk
name: blank-disk
virtualMachineName: linux-vm
EOF
После создания VirtualMachineBlockDeviceAttachment может находиться в следующих состояниях (фазах):
Pending— ожидание готовности всех зависимых ресурсов.InProgress— идет процесс подключения устройства.Attached— устройство подключено.
Диагностика проблем с ресурсом осуществляется путем анализа информации в блоке .status.conditions.
Проверьте состояние вашего ресурса:
d8 k get vmbda attach-blank-disk
Пример вывода:
NAME PHASE VIRTUAL MACHINE NAME AGE
attach-blank-disk Attached linux-vm 3m7s
Подключитесь к виртуальной машине и удостоверитесь, что диск подключен:
d8 v ssh cloud@linux-vm --local-ssh --command "lsblk"
Пример вывода:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 10G 0 disk <--- статично подключенный диск linux-vm-root
|-sda1 8:1 0 9.9G 0 part /
|-sda14 8:14 0 4M 0 part
`-sda15 8:15 0 106M 0 part /boot/efi
sdb 8:16 0 1M 0 disk <--- cloudinit
sdc 8:32 0 95.9M 0 disk <--- динамически подключенный диск blank-disk
Для отключения диска от виртуальной машины удалите ранее созданный ресурс:
d8 k delete vmbda attach-blank-disk
Подключение образов, осуществляется по аналогии. Для этого в качестве kind указать VirtualImage или ClusterVirtualImage и имя образа:
d8 k apply -f - <<EOF
apiVersion: virtualization.deckhouse.io/v1alpha2
kind: VirtualMachineBlockDeviceAttachment
metadata:
name: attach-ubuntu-iso
spec:
blockDeviceRef:
kind: VirtualImage # или ClusterVirtualImage
name: ubuntu-iso
virtualMachineName: linux-vm
EOF
Как работать с дополнительными блочными устройствами в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация» → «Виртуальные машины».
- Из списка выберите необходимую ВМ и нажмите на её имя.
- На вкладке «Конфигурация» прокрутите страницу до раздела «Диски и образы».
- В секции «Дополнительные диски» доступны следующие действия:
Добавить— подключить к ВМ новый диск или образ;Извлечь— отключить устройство от ВМ (образ или диск остаётся в проекте, его можно снова подключить к этой или другой ВМ);Удалить— удалить сам ресурс образа или диска из кластера (после удаления его нельзя использовать повторно);Изменить размер— изменить размер диска.
Именование дисков в гостевой ОС
Имена блочных устройств (/dev/sda, /dev/sdb, /dev/sdc и т. д.) присваиваются ядром Linux в порядке обнаружения устройств при загрузке. Этот порядок может меняться между перезагрузками, поэтому имена устройств могут измениться даже при неизменных SCSI-адресах.
Если использовать /dev/sdX в конфигурационных файлах (например, /etc/fstab) или скриптах, после перезагрузки ВМ можно смонтировать не тот диск или получить некорректную работу системы.
Пример:
После первой загрузки ВМ:
$ lsscsi
[0:0:0:1] disk QEMU QEMU HARDDISK /dev/sda
[0:0:0:2] disk QEMU QEMU HARDDISK /dev/sdb
После перезагрузки ВМ:
$ lsscsi
[0:0:0:1] disk QEMU QEMU HARDDISK /dev/sdb
[0:0:0:2] disk QEMU QEMU HARDDISK /dev/sda
SCSI-адреса (0:0:0:1, 0:0:0:2) остаются неизменными, но имена устройств (/dev/sda, /dev/sdb) меняются местами.
Используйте стабильные идентификаторы вместо /dev/sdX:
/dev/disk/by-uuid/— по UUID разделов (предпочтительно для/etc/fstab);/dev/disk/by-path/— по SCSI пути подключения;/dev/disk/by-id/— по SCSI ID устройства.
В конфигурационных файлах и скриптах используйте UUID разделов или символические ссылки из /dev/disk/by-* вместо имён /dev/sdX.
Именование сетевых интерфейсов в гостевой ОС
В системах без поддержки предсказуемого именования интерфейсов (predictable network interface naming) имена сетевых интерфейсов (eth0, eth1, eth2 и т. д.) присваиваются ядром Linux в порядке обнаружения устройств при загрузке. При добавлении новых сетевых интерфейсов или изменении порядка сетей в .spec.networks порядок интерфейсов может измениться, из-за чего IP-адреса могут быть назначены не тем интерфейсам.
Использование ethX в конфигурационных файлах (например, /etc/network/interfaces, netplan, systemd-networkd) или в скриптах при добавлении новых интерфейсов или изменении порядка сетей может привести к сбоям в работе сети или подключению к неверной сети.
В современных дистрибутивах с systemd (Ubuntu 16.04+, Debian 9+, CentOS 7+, RHEL 7+) по умолчанию используются предсказуемые имена интерфейсов (enpXsY, ensX, enoX), которые основаны на физических характеристиках устройства (PCI координаты) и остаются стабильными между перезагрузками и при добавлении новых интерфейсов.
Однако даже при использовании предсказуемых имён рекомендуется привязывать конфигурацию сети к MAC-адресам интерфейсов для гарантированной стабильности, особенно при изменении порядка сетей в .spec.networks или добавлении новых интерфейсов.
Пример для систем без предсказуемого именования:
Изначально ВМ имеет два интерфейса:
$ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
После добавления нового интерфейса в начало списка .spec.networks и перезагрузки ВМ:
$ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 # Новый интерфейс
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 # Старый eth0
4: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 # Старый eth1
MAC-адреса остаются неизменными, но имена интерфейсов (eth0, eth1) сдвигаются, что может привести к назначению IP-адресов не тем интерфейсам.
Используйте стабильные идентификаторы вместо ethX:
enpXsY— предсказуемые имена на основе физического расположения (systemd networkd naming scheme, включены по умолчанию в современных системах);- привязка по MAC-адресу — в конфигурации
netplan,systemd-networkdили/etc/network/interfaces(предпочтительно для гарантированной стабильности).
В конфигурационных файлах и скриптах используйте стабильные имена интерфейсов (enpXsY) или привязку по MAC-адресу вместо имён ethX.
Предсказуемый порядок интерфейсов соблюдается только в гостевых ОС с systemd (например, Ubuntu, Debian). В Alpine и других дистрибутивах без systemd порядок может не совпадать.
Организация взаимодействия с ВМ
К виртуальным машинам можно обращаться напрямую по их фиксированным IP-адресам. Однако такой подход имеет ограничения: прямое использование IP-адресов требует ручного управления, усложняет масштабирование и делает инфраструктуру менее гибкой. Альтернативой служат сервисы — механизм, который абстрагирует доступ к ВМ, предоставляя логические точки входа вместо привязки к физическим адресам.
Если подключение к ВМ с узла кластера не проходит, проверьте NetworkPolicy в проекте. Сетевые политики проекта могут ограничивать доступ к ВМ, в том числе соединения с узлов кластера.
Сервисы упрощают взаимодействие как с отдельными ВМ, так и с группами подобных ВМ. Например, тип сервиса ClusterIP создаёт фиксированный внутренний адрес, через который можно обращаться как к одной, так и к группе ВМ, независимо от их реальных IP-адресов. Это позволяет другим компонентам системы взаимодействовать с ресурсами через стабильное имя или IP, автоматически направляя трафик к нужным машинам.
Сервисы также служат инструментом балансировки нагрузки: они равномерно распределяют запросы между всеми связанными машинами, обеспечивая отказоустойчивость и простоту расширения без необходимости перенастройки клиентов.
Для сценариев, где важен прямой доступ внутри кластера к конкретным ВМ (например, для диагностики или настройки кластеров), можно использовать headless-сервисы. Headless-сервисы не назначают общий IP, а вместо этого связывают DNS-имя с реальными адресами всех связанных машин. Запрос к такому имени возвращает список IP, что позволяет выбирать нужную ВМ вручную, сохраняя при этом удобство использования предсказуемых DNS-записей.
Для внешнего доступа сервисы дополняются механизмами вроде NodePort, который открывает порт на узле кластера, LoadBalancer, автоматически создающим облачный балансировщик нагрузки, или Ingress, управляющим маршрутизацией HTTP/HTTPS-трафика.
Все эти подходы объединяет способность скрывать сложность инфраструктуры за простыми интерфейсами: клиенты работают с конкретным адресом, а система сама решает, как направить запрос к нужной ВМ, даже если их количество или состояние меняется.
Имя сервиса формируется как <service-name>.<namespace or project name>.svc.<clustername>, или более коротко: <service-name>.<namespace or project name>.svc. Например, если имя вашего сервиса — http, а неймспейс — default, то полное DNS-имя будет http.default.svc.cluster.local.
Принадлежность ВМ к сервису определяется набором лейблов. Чтобы установить лейблы на ВМ в контексте управления инфраструктурой, используйте следующую команду:
d8 k label vm <vm-name> label-name=label-value
Пример команды:
d8 k label vm linux-vm app=nginx
Пример вывода команды:
virtualmachine.virtualization.deckhouse.io/linux-vm labeled
Как добавлять лейблы и аннотации на ВМ в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация» → «Виртуальные машины».
- Из списка выберите необходимую ВМ и нажмите на её имя.
- Перейдите на вкладку «Мета».
- В секции «Лейблы» Вы можете добавить лейблы.
- В секции «Аннотации» Вы можете добавить аннотации.
- Нажмите «Добавить» в нужной секции.
- Во всплывающем окне можете задать «Ключ», «Значение» ключа.
- Для подтверждения параметров ключа нажмите кнопку «Enter».
- Нажмите на появившуюся кнопку «Сохранить».
Headless сервис
Headless-сервис позволяет легко направлять запросы внутри кластера без необходимости в балансировке нагрузки. Вместо этого он просто возвращает все IP-адреса виртуальных машин, подключенных к этому сервису.
Даже если вы используете headless-сервис только для одной виртуальной машины, это все равно полезно. Благодаря использованию DNS-имени, вы можете обращаться к машине, не завися от ее текущего IP-адреса. Это упрощает управление и настройку, потому что другие приложения внутри кластера могут использовать это DNS-имя для подключения вместо использования конкретного IP-адреса, который может измениться.
Пример создания headless-сервиса:
d8 k apply -f - <<EOF
apiVersion: v1
kind: Service
metadata:
name: http
namespace: default
spec:
clusterIP: None
selector:
# Лейбл по которому сервис определяет на какую виртуальную машину направлять трафик.
app: nginx
EOF
После создания, к ВМ или группе ВМ можно будет обратиться по имени: http.default.svc
Сервис с типом ClusterIP
ClusterIP — это стандартный тип сервиса, который предоставляет внутренний IP-адрес для доступа к сервису внутри кластера. Этот IP-адрес используется для маршрутизации трафика между различными компонентами системы. ClusterIP позволяет виртуальным машинам взаимодействовать друг с другом через предсказуемый и стабильный IP-адрес, что упрощает внутреннюю коммуникацию в кластере.
Пример конфигурации ClusterIP:
d8 k apply -f - <<EOF
apiVersion: v1
kind: Service
metadata:
name: http
spec:
selector:
# Лейбл по которому сервис определяет на какую виртуальную машину направлять трафик.
app: nginx
EOF
Как выполнить операцию в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Сеть» → «Services».
- В открывшемся окне выполните настройки сервиса.
- Нажмите на кнопку «Создать».
Сервис с типом NodePort
NodePort — это расширение сервиса ClusterIP, которое обеспечивает доступ к сервису через заданный порт на всех узлах кластера. Это делает сервис доступным извне кластера через комбинацию IP адреса узла и порта.
NodePort подходит для сценариев, когда требуется непосредственный доступ к сервису извне кластера без использования внешнего балансировщика.
Создайте следующий сервис:
d8 k apply -f - <<EOF
apiVersion: v1
kind: Service
metadata:
name: linux-vm-nginx-nodeport
spec:
type: NodePort
selector:
# Лейбл по которому сервис определяет на какую виртуальную машину направлять трафик.
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 31880
EOF
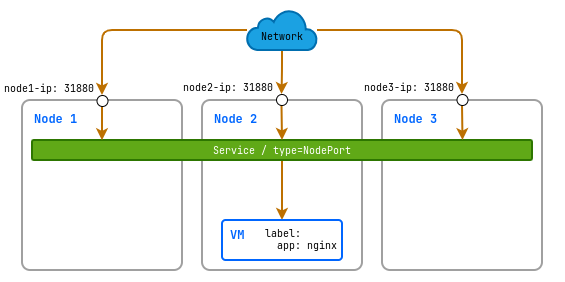
В данном примере будет создан сервис с типом NodePort, который открывает внешний порт 31880 на всех узлах вашего кластера. Этот порт будет направлять входящий трафик на внутренний порт 80 виртуальной машины, где запущено приложение Nginx.
Если не указывать значение nodePort явно, для сервиса будет назначен произвольный порт, который можно посмотреть в статусе сервиса, сразу после его создания.
Сервис с типом LoadBalancer
LoadBalancer — это тип сервиса, который автоматически создает внешний балансировщик нагрузки с постоянным IP-адресом. Этот балансировщик распределяет входящий трафик среди виртуальных машин, обеспечивая доступность сервиса из интернета.
d8 k apply -f - <<EOF
apiVersion: v1
kind: Service
metadata:
name: linux-vm-nginx-lb
spec:
type: LoadBalancer
selector:
# Лейбл по которому сервис определяет на какую виртуальную машину направлять трафик
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
EOF
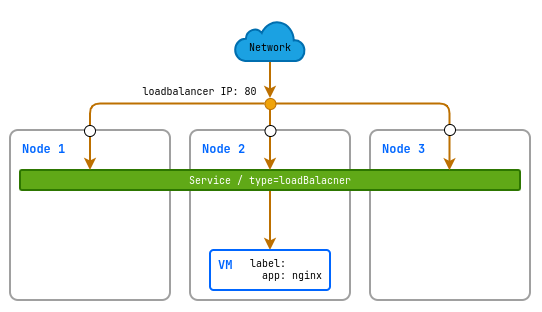
Публикация сервисов ВМ с использованием Ingress
Ingress позволяет управлять входящими HTTP/HTTPS запросами и маршрутизировать их к различным серверам в рамках вашего кластера. Это наиболее подходящий метод, если вы хотите использовать доменные имена и SSL-терминацию для доступа к вашим виртуальным машинам.
Для публикации сервиса виртуальной машины через Ingress необходимо создать следующие ресурсы:
Внутренний сервис для связки с Ingress. Пример:
d8 k apply -f - <<EOF
apiVersion: v1
kind: Service
metadata:
name: linux-vm-nginx
spec:
selector:
# лейбл по которому сервис определяет на какую виртуальную машину направлять трафик
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
EOF
И ресурс Ingress для публикации. Пример:
d8 k apply -f - <<EOF
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: linux-vm
spec:
rules:
- host: linux-vm.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: linux-vm-nginx
port:
number: 80
EOF
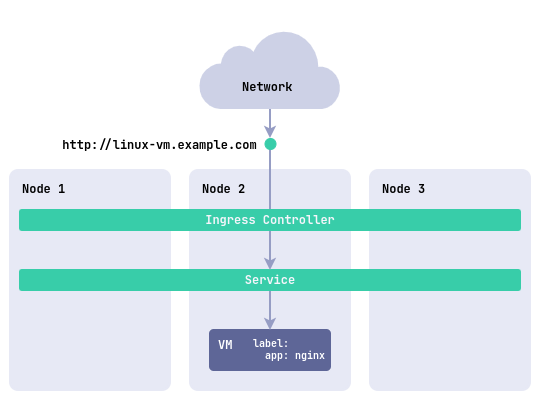
Как опубликовать сервис ВМ с использованием Ingress в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Сеть» → «Ingresses».
- Нажмите кнопку «Создать Ingress».
- В открывшемся окне выполните настройки сервиса.
- Нажмите на кнопку «Создать».
Живая миграция ВМ
Живая миграция виртуальных машин — это процесс перемещения работающей ВМ с одного физического узла на другой без её отключения. Эта функция играет ключевую роль в управлении виртуализованной инфраструктурой, обеспечивая непрерывность работы приложений во время технического обслуживания, балансировки нагрузки или обновлений.
Как работает живая миграция
Процесс живой миграции включает несколько этапов:
-
Создание нового экземпляра ВМ
На целевом узле создаётся новая ВМ в приостановленном состоянии. Её конфигурация (процессор, диски, сеть) копируется с исходного узла.
-
Первичная передача памяти
Вся оперативная память ВМ копируется на целевой узел по сети. Это называется первичной передачей.
-
Отслеживание изменений (Dirty Pages)
Пока память передаётся, ВМ продолжает работать на исходном узле и может изменять некоторые страницы памяти. Такие страницы называются «грязными» (dirty pages), и гипервизор их помечает.
-
Итеративная синхронизация
После первичной передачи начинается повторная отправка только изменённых страниц. Этот процесс повторяется в несколько циклов:
- Чем выше нагрузка на ВМ, тем больше «грязных» страниц появляется, и тем дольше длится миграция.
- При хорошей пропускной способности сети объём несинхронизированных данных постепенно уменьшается.
-
Финальная синхронизация и переключение
Когда количество «грязных» страниц становится минимальным, ВМ на исходном узле приостанавливается (обычно на 100 миллисекунд):
- Оставшиеся изменения памяти передаются на целевой узел.
- Состояние процессора, устройств и открытых соединений синхронизируется.
- ВМ запускается на новом узле, а исходная копия удаляется.
До момента переключения ВМ на новый узел (Фаза 5), ВМ на исходном узле продолжает работать в обычном режиме и предоставлять сервис пользователям.
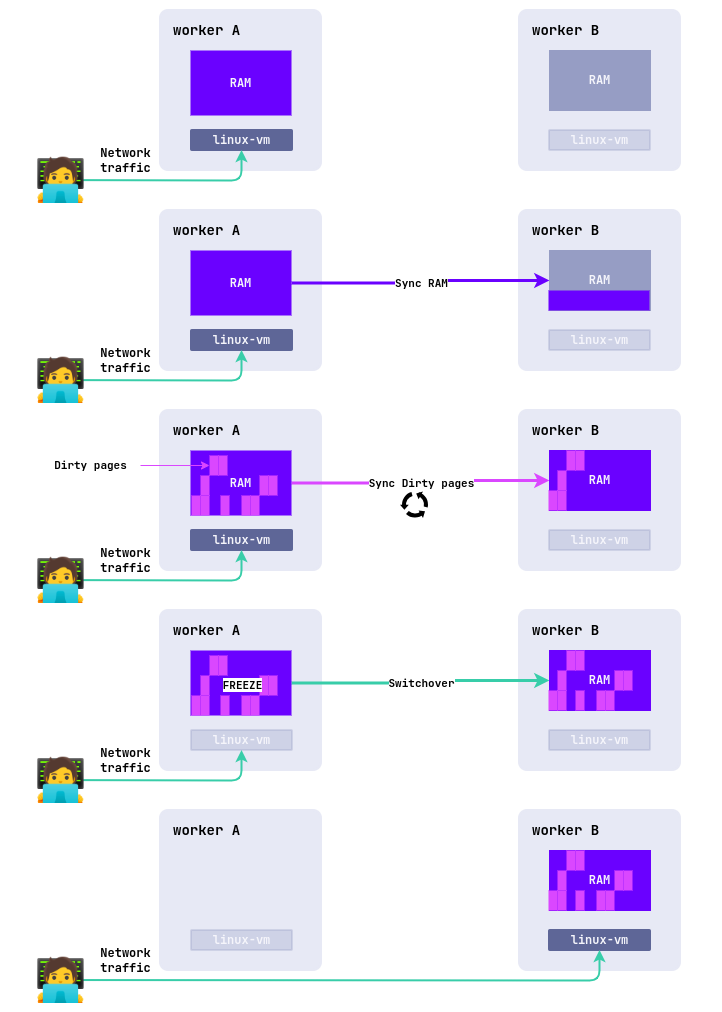
Требования и ограничения
Для успешной живой миграции необходимо выполнить определённые требования. Несоблюдение этих требований приводит к ограничениям и проблемам при миграции.
-
Доступность дисков: Все подключённые к ВМ диски должны быть доступны на целевом узле, иначе миграция будет невозможна. Для сетевых хранилищ (NFS, Ceph и т.д.) это требование обычно выполняется автоматически, так как диски доступны на всех узлах кластера. Для локальных хранилищ ситуация иная: хранилище должно быть доступно для создания нового локального тома на целевом узле. Если локальное хранилище есть только на исходном узле, миграция не может быть выполнена.
-
Пропускная способность сети: Скорость сети критически важна для живой миграции. При низкой пропускной способности увеличивается количество итераций синхронизации памяти, возрастает время простоя ВМ на финальном этапе миграции, а в худшем случае миграция может не завершиться из-за превышения таймаута. Для управления процессом миграции настройте политику живой миграции
.spec.liveMigrationPolicyв настройках ВМ. При проблемах с сетью используйте механизм AutoConverge (см. раздел Миграции при недостаточной пропускной способности сети). -
Версии ядер на узлах: Для стабильной работы живой миграции на всех узлах кластера должна использоваться идентичная версия ядра Linux. Различия в версиях ядра могут привести к несовместимости интерфейсов, системных вызовов и особенностей работы с ресурсами, что нарушает процесс миграции виртуальных машин.
-
Совместимость процессоров: Совместимость процессоров зависит от типа CPU, указанного в классе виртуальной машины. При использовании типа
Hostмиграция возможна только между узлами с похожими типами процессоров: миграция между узлами с процессорами Intel и AMD не работает, также не работает между разными поколениями CPU из-за различий в наборе инструкций. При использовании типаHostPassthroughВМ может мигрировать только на узел с точно таким же процессором, как на исходном узле. Для обеспечения совместимости миграции между узлами с разными процессорами используйте типыDiscovery,ModelилиFeaturesв классе виртуальной машины. -
Время выполнения миграции: Для живой миграции устанавливается таймаут завершения, который рассчитывается по формуле:
Таймаут завершения = 800 секунд × (Размер памяти в GiB + Размер диска в GiB (если используется Block Migration)). Если миграция не завершается в течение этого времени, операция считается неудачной и отменяется. Например, для виртуальной машины с 4 GiB памяти и 20 GiB диска таймаут составит800 секунд × (4 GiB + 20 GiB) = 19200 секунд (320 минут или ~5,3 часа). При низкой скорости сети или высокой нагрузке на ВМ миграция может не успеть завершиться в отведённое время.
Как выполнить живую миграцию ВМ
Рассмотрим пример. Перед запуском миграции посмотрите текущий статус виртуальной машины:
d8 k get vm
Пример вывода:
NAME PHASE NODE IPADDRESS AGE
linux-vm Running virtlab-pt-1 10.66.10.14 79m
Мы видим что на данный момент она запущена на узле virtlab-pt-1.
Для миграции виртуальной машины с одного узла на другой с учётом требований к её размещению используйте команду:
d8 v evict -n <namespace> <vm-name> [--force]
Выполнение этой команды приводит к созданию ресурса VirtualMachineOperations.
Флаг --force при выполнении миграции виртуальной машины активирует специальный механизм AutoConverge (подробнее см. раздел Миграции при недостаточной пропускной способности сети). Этот механизм автоматически снижает нагрузку на процессор виртуальной машины (замедляет её CPU), если требуется ускорить завершение миграции и обеспечить её успешное выполнение, даже если передача памяти ВМ идёт слишком медленно. Используйте этот флаг, если стандартная миграция не может завершиться из-за высокой активности ВМ.
Запустить миграцию можно также создав ресурс VirtualMachineOperations (vmop) с типом Evict вручную:
d8 k create -f - <<EOF
apiVersion: virtualization.deckhouse.io/v1alpha2
kind: VirtualMachineOperation
metadata:
generateName: evict-linux-vm-
spec:
# Имя виртуальной машины.
virtualMachineName: linux-vm
# Операция для миграции.
type: Evict
# Разрешить замедление процессора механизмом AutoConverge, для гарантии, что миграция выполнится.
force: true
EOF
Для отслеживания миграции виртуальной машины сразу после создания ресурса vmop, выполните команду:
d8 k get vm -w
Пример вывода:
NAME PHASE NODE IPADDRESS AGE
linux-vm Running virtlab-pt-1 10.66.10.14 79m
linux-vm Migrating virtlab-pt-1 10.66.10.14 79m
linux-vm Migrating virtlab-pt-1 10.66.10.14 79m
linux-vm Running virtlab-pt-2 10.66.10.14 79m
Прервать любую живую миграцию, пока она находится в фазе Pending или InProgress, можно, удалив соответствующий ресурс VirtualMachineOperations.
Как выполнить живую миграцию ВМ в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация» → «Виртуальные машины».
- Из списка выберите нужную виртуальную машину и нажмите кнопку с многоточием.
- Во всплывающем меню выберите «Мигрировать».
- Во всплывающем окне подтвердите или отмените миграцию.
Настройка политики миграции
Политика миграции определяет, когда использовать механизм AutoConverge (замедление процессора) для гарантированного завершения миграции.
Механизм AutoConverge помогает завершить миграцию даже при низкой пропускной способности сети, что позволяет с высокой вероятностью успешно завершить операцию. Однако он замедляет процессор виртуальной машины, что может повлиять на производительность приложений, работающих на виртуальной машине.
Механизм AutoConverge работает в два этапа:
-
Замедление процессора виртуальной машины
Гипервизор постепенно снижает частоту процессора исходной виртуальной машины. Это уменьшает скорость появления новых «грязных» страниц. Чем выше нагрузка на виртуальную машину, тем сильнее замедление.
-
Автоматическое завершение миграции
Как только скорость передачи данных превышает скорость изменения памяти, запускается финальная синхронизация, и виртуальная машина переключается на новый узел.
Для настройки политики миграции используйте параметр .spec.liveMigrationPolicy в конфигурации виртуальной машины. Допустимые значения параметра:
AlwaysSafe— миграция всегда выполняется без замедления процессора (AutoConverge не используется). Подходит для случаев, когда важна максимальная производительность виртуальной машины, но требует высокой пропускной способности сети.PreferSafe(используется в качестве политики по умолчанию) — миграция выполняется без замедления процессора (AutoConverge не используется). Однако можно запустить миграцию с замедлением процессора, используя ресурс VirtualMachineOperation с параметрамиtype=Evictиforce=true.AlwaysForced— миграция всегда использует AutoConverge, то есть процессор замедляется при необходимости. Это гарантирует завершение миграции даже при плохой сети, но может снизить производительность виртуальной машины.PreferForced— миграция использует AutoConverge, то есть процессор замедляется при необходимости. Однако можно запустить миграцию без замедления процессора, используя ресурс VirtualMachineOperation с параметрамиtype=Evictиforce=false.
Миграции при недостаточной пропускной способности сети
При живой миграции виртуальной машины может возникнуть ситуация, когда пропускной способности сети недостаточно для передачи данных быстрее, чем они изменяются в памяти виртуальной машины. В этом случае количество «грязных» страниц продолжает расти, и миграция может не завершиться в течение таймаута.
Для решения этой проблемы используется механизм AutoConverge, который настраивается через политику миграции.
Чтобы понять, что пропускной способности сети не хватает для живой миграции виртуальной машины, проверьте графики в разделе «Namespace / Virtual Machine» → «VM Status details» → «Live migration memory metrics»:
- Processed memory rate (скорость передачи памяти) меньше Dirty memory rate (скорость изменения памяти);
- Remaining memory rate (оставшаяся память) долго не уменьшается.
Это означает, что сеть стала узким местом для миграции.
Пример ситуации, когда миграция не может быть завершена из-за недостаточной пропускной способности сети: внутри виртуальной машины непрерывно меняется память при помощи stress-ng.
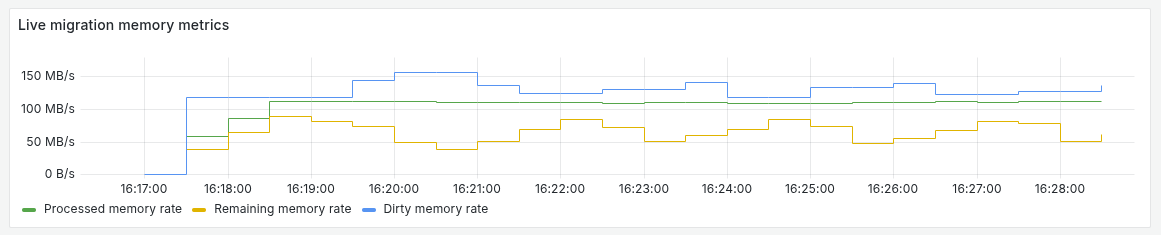
Пример выполнения миграции той же виртуальной машины с использованием флага --force команды d8 v evict (который включает механизм AutoConverge): здесь хорошо видно, что частота процессора снижается поэтапно, чтобы уменьшить скорость изменения памяти.
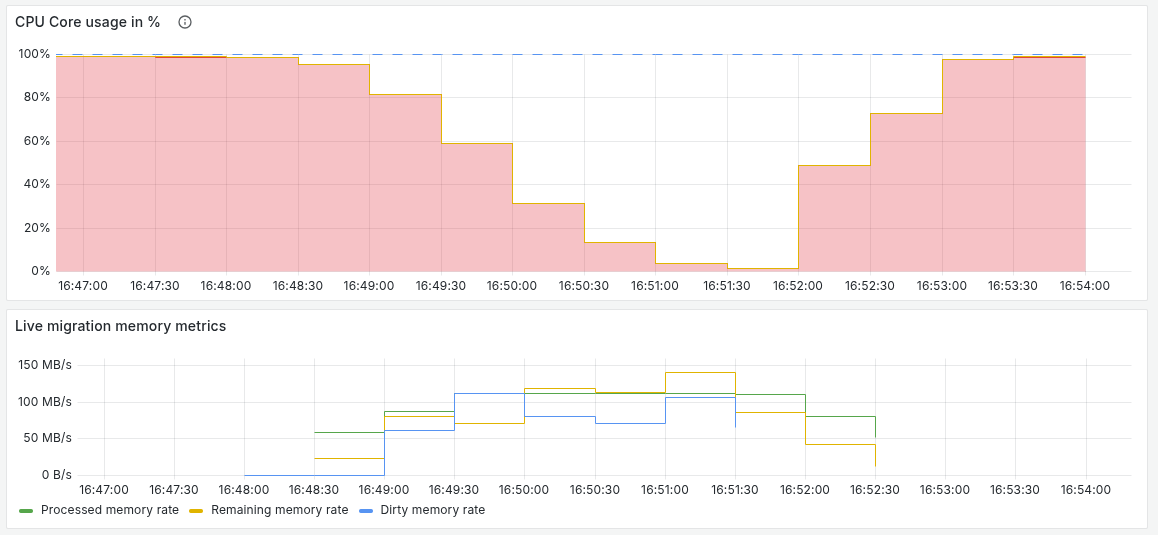
Если сеть ограничивает скорость миграции, можно:
-
Дождаться, когда операция завершится с ошибкой из-за таймаута.
-
Отменить текущую операцию миграции, удалив объект
vmop:d8 k delete vmop <имя-операции> -
Повторно запустить миграцию с использованием флага
--force, чтобы включить механизм AutoConverge. Использование флага--forceдолжно соответствовать текущей политике миграции виртуальной машины.
Миграции, запускаемые системой
Миграция может осуществляться автоматически при следующих системных событиях:
- обновление «прошивки» виртуальной машины;
- перераспределение нагрузки в кластере;
- перевод узла в режим технического обслуживания (drain узла);
- изменение параметров размещения ВМ (недоступно в Community-редакции).
Триггером к живой миграции является появление ресурса VirtualMachineOperations с типом Evict.
В таблице приведены префиксы названия ресурса VirtualMachineOperations с типом Evict, создаваемые для живых миграций, вызванных системными событиями:
| Вид системного события | Префикс имени ресурса |
|---|---|
| Обновление «прошивки» | firmware-update-\* |
| Перераспределение нагрузки | evacuation-\* |
| Drain узла | evacuation-\* |
| Изменение параметров размещения | nodeplacement-update-\* |
| Миграция хранилища дисков | volume-migration-\* |
Данный ресурс может находиться в следующих состояниях:
Pending— ожидается выполнение операции;InProgress— живая миграция выполняется;Completed— живая миграция виртуальной машины завершилась успешно;Failed— живая миграция виртуальной машины завершилась с ошибкой.
Посмотреть активные операции можно с использованием команды:
d8 k get vmop
Пример вывода:
NAME PHASE TYPE VIRTUALMACHINE AGE
firmware-update-fnbk2 Completed Evict linux-vm 1m
Для отмены миграции удалите соответствующий ресурс.
Как посмотреть активные операции в веб-интерфейсе:
- Перейдите на вкладку «Проекты» и выберите нужный проект.
- Перейдите в раздел «Виртуализация» → «Виртуальные машины».
- Из списка выберите необходимую ВМ и нажмите на её имя.
- Перейдите на вкладку «События».
Живая миграция ВМ при изменении параметров размещения
Данная функция недоступна в CE редакции
Рассмотрим механизм миграции на примере кластера с двумя группами узлов (NodeGroups): green и blue . Допустим, виртуальная машина (ВМ) изначально запущена на узле группы green , а её конфигурация не содержит ограничений на размещение.
Шаг 1. Добавление параметра размещения Укажем в спецификации ВМ требование к размещению в группе green :
spec:
nodeSelector:
node.deckhouse.io/group: green
После сохранения изменений ВМ продолжит работать на текущем узле, так как условие nodeSelector уже выполняется.
Шаг 2. Изменение группы размещения Изменим требование на размещение в группе blue :
spec:
nodeSelector:
node.deckhouse.io/group: blue
Теперь текущий узел (группы green) не соответствует новым условиям. Система автоматически создаст объект VirtualMachineOperations типа Evict, что инициирует живую миграцию ВМ на доступный узел группы blue.
Пример вывода ресурса
NAME PHASE TYPE VIRTUALMACHINE AGE
nodeplacement-update-dabk4 Completed Evict linux-vm 1m
Сбор отладочной информации
Для использования команды collect-debug-info требуется версия d8 v0.27.0 или выше.
Команда collect-debug-info собирает диагностические данные о ВМ и всех связанных ресурсах в единый сжатый архив.
Команда собирает следующую информацию:
- конфигурацию виртуальной машины;
- операции над виртуальной машиной;
- информацию о миграциях;
- блочные устройства;
- связанные PVC и PV;
- поды, связанные с ВМ, включая их логи (последние 10000 строк);
- события (Events) для всех связанных ресурсов;
- XML-конфигурацию домена ВМ.
Результат работы команды записывается в сжатый архив (tar.gz), который выводится в stdout. Для сохранения архива необходимо перенаправить вывод в файл.
Пример использования:
# Сбор отладочной информации для виртуальной машины 'linux-vm'
d8 v collect-debug-info linux-vm > debug-info.tar.gz
# Сбор отладочной информации для ВМ с указанием неймспейса
d8 v collect-debug-info linux-vm -n mynamespace > debug-info.tar.gz
# Сбор отладочной информации для ВМ с указанием полного имени (name.namespace)
d8 v collect-debug-info linux-vm.mynamespace > debug-info.tar.gz
Команда не может выводить данные напрямую в терминал. Обязательно перенаправьте вывод в файл, иначе команда завершится с ошибкой.
После выполнения команды вы получите архив debug-info.tar.gz, который содержит все собранные данные в формате YAML (для ресурсов) и текстовые файлы (для логов). Этот архив можно передать в службу технической поддержки для анализа проблем.
Настройка сети
IP-адреса ВМ
Блок .spec.settings.virtualMachineCIDRs в конфигурации модуля virtualization задает список подсетей для назначения IP-адресов виртуальным машинам (общий пул IP-адресов). Все адреса в этих подсетях доступны для использования, за исключением первого (адрес сети) и последнего (широковещательный адрес). Например:
- Для подсети
10.20.30.0/26: зарезервированы10.20.30.0и10.20.30.63. - Для подсети
10.20.30.64/26: зарезервированы10.20.30.64и10.20.30.127.
Ресурс VirtualMachineIPAddressLease (vmipl): кластерный ресурс, который управляет арендой IP-адресов из общего пула, указанного в virtualMachineCIDRs.
Чтобы посмотреть список аренд IP-адресов (vmipl), используйте команду:
d8 k get vmipl
Пример вывода:
NAME VIRTUALMACHINEIPADDRESS STATUS AGE
ip-10-66-10-14 {"name":"linux-vm-7prpx","namespace":"default"} Bound 12h
Ресурс VirtualMachineIPAddres (vmip): проектный/неймспейсный ресурс, который отвечает за резервирование арендованных IP-адресов и их привязку к виртуальным машинам. IP-адреса могут выделяться автоматически или по явному запросу.
После создания ресурс VirtualMachineIPAddress может находиться в следующих состояниях:
Pending— выполняется создание ресурса;Bound— ресурс VirtualMachineIPAddress привязан к ресурсу VirtualMachineIPAddressLease;Attached— ресурс VirtualMachineIPAddress подключен к ресурсу VirtualMachine.
По умолчанию IP-адрес виртуальной машине назначается автоматически из подсетей, определенных в модуле и закрепляется за ней до её удаления. Проверить назначенный IP-адрес можно с помощью команды:
d8 k get vmip
Пример вывода:
NAME ADDRESS STATUS VM AGE
linux-vm-7prpx 10.66.10.14 Attached linux-vm 12h
Алгоритм автоматического присвоения IP-адреса виртуальной машине выглядит следующим образом:
- Пользователь создает виртуальную машину с именем
<vmname>. - Контроллер модуля автоматически создает ресурс
vmipс именем<vmname>-<hash>, чтобы запросить IP-адрес и связать его с виртуальной машиной. - Для этого
vmipсоздается ресурс арендыvmipl, который выбирает случайный IP-адрес из общего пула. - Как только ресурс
vmipсоздан, виртуальная машина получает назначенный IP-адрес.
IP-адрес виртуальной машине назначается автоматически из подсетей, определенных в модуле, и остается закрепленным за машиной до её удаления. После удаления виртуальной машины ресурс vmip также удаляется, но IP-адрес временно остается закрепленным за проектом или неймспейсом и может быть повторно запрошен явно.
С полным описанием параметров конфигурации ресурсов vmip и vmipl машин можно ознакомиться по ссылкам:
Как запросить требуемый ip-адрес?
-
Создайте ресурс
vmip:d8 k apply -f - <<EOF apiVersion: virtualization.deckhouse.io/v1alpha2 kind: VirtualMachineIPAddress metadata: name: linux-vm-custom-ip spec: staticIP: 10.66.20.77 type: Static EOF -
Создайте новую или измените существующую виртуальную машину и в спецификации укажите требуемый ресурс
vmipявно:spec: virtualMachineIPAddressName: linux-vm-custom-ip
Как сохранить присвоенный ВМ ip-адрес?
Чтобы автоматически выданный ip-адрес виртуальной машины не удалился вместе с самой виртуальной машиной выполните следующие действия.
Получите название ресурса vmip для заданной виртуальной машины:
d8 k get vm linux-vm -o jsonpath="{.status.virtualMachineIPAddressName}"
Пример вывода:
linux-vm-7prpx
Удалите блоки .metadata.ownerReferences из найденного ресурса:
d8 k patch vmip linux-vm-7prpx --type=merge --patch '{"metadata":{"ownerReferences":null}}'
# Или внесите аналогичные изменения, отредактировав ресурс.
d8 k edit vmip linux-vm-7prpx
После удаления виртуальной машины, ресурс vmip сохранится и его можно будет переиспользовать снова во вновь созданной виртуальной машине:
spec:
virtualMachineIPAddressName: linux-vm-7prpx
Даже если ресурс vmip будет удален, IP-адрес остаётся арендованным для текущего проекта/неймспейса еще 10 минут. Поэтому существует возможность вновь его занять по запросу:
d8 k apply -f - <<EOF
apiVersion: virtualization.deckhouse.io/v1alpha2
kind: VirtualMachineIPAddress
metadata:
name: linux-vm-custom-ip
spec:
staticIP: 10.66.20.77
type: Static
EOF
Дополнительные сетевые интерфейсы
Для работы с дополнительными сетями необходимо, чтобы модуль sdn был активирован.
Виртуальные машины могут быть подключены к дополнительным сетям — проектным (Network) или кластерным (ClusterNetwork).
Для этого необходимо указать желаемые сети в конфигурационном разделе .spec.networks. Если данный блок не задан (что является значением по умолчанию), ВМ будет использовать только основную сеть кластера.
Указание основной сети кластера (type: Main) в .spec.networks является опциональным. Если вам не требуется подключение к основной сети кластера, можно использовать только дополнительные сети (Network или ClusterNetwork).
Однако если основная сеть указана, она обязательно должна быть первой в списке .spec.networks.
Особенности и важные моменты работы с дополнительными сетевыми интерфейсами:
- порядок перечисления сетей в
.spec.networksопределяет порядок подключения интерфейсов внутри виртуальной машины; - добавление или удаление дополнительных сетей вступает в силу только после перезагрузки ВМ;
- чтобы сохранить порядок сетевых интерфейсов внутри гостевой операционной системы, рекомендуется добавлять новые сети в конец списка
.spec.networks(не менять порядок уже существующих); - политики сетевой безопасности (NetworkPolicy) не применяются к дополнительным сетевым интерфейсам;
- параметры сети (IP-адреса, шлюзы, DNS и т.д.) для дополнительных сетей настраиваются вручную изнутри гостевой ОС (например, с помощью Cloud-Init).
При настройке сетевых интерфейсов в гостевой ОС используйте стабильные идентификаторы (предсказуемые имена enpXsY или привязку по MAC-адресу) вместо имён ethX. Подробнее см. раздел Именование сетевых интерфейсов в гостевой ОС.
На гостевой системе Linux с несколькими интерфейсами в одной подсети может возникать проблема ARP Flux, при которой ядро отвечает на ARP-запросы через произвольный интерфейс, а не через тот, на который пришёл запрос, что приводит к нестабильному соединению и потере пакетов из-за некорректного MAC-адреса в кеше маршрутизаторов.
Чтобы это исправить, установите параметры, которые заставляют систему отвечать на запросы строго через интерфейс с целевым IP и использовать корректный исходный адрес:
sysctl -w net.ipv4.conf.all.arp_ignore=1
sysctl -w net.ipv4.conf.all.arp_announce=2
Пример для cloud-init:
write_files:
- path: /etc/sysctl.d/90-arp-strict.conf
content: |
net.ipv4.conf.all.arp_ignore=1
net.ipv4.conf.all.arp_announce=2
Подробнее см. документацию IP sysctl.
Пример подключения ВМ к основной сети кластера и проектной сети user-net:
spec:
networks:
- type: Main # Если указана, должна быть первой
- type: Network # Тип сети (Network \ ClusterNetwork)
name: user-net # Название сети
Пример подключения к нескольким сетям, включая кластерную сеть corp-net:
spec:
networks:
- type: Main # Если указана, должна быть первой
- type: Network
name: user-net
- type: ClusterNetwork
name: corp-net # Название сети
Пример подключения ВМ только к дополнительным сетям (без основной сети кластера):
spec:
networks:
- type: Network
name: isolated-net
- type: ClusterNetwork
name: corp-net
Информацию о подключённых сетях и их MAC-адресах можно посмотреть в статусе ВМ:
status:
networks:
- type: Main
- type: Network
name: user-net
macAddress: aa:bb:cc:dd:ee:01
- type: ClusterNetwork
name: corp-net
macAddress: aa:bb:cc:dd:ee:02
Для каждого дополнительного сетевого интерфейса автоматически создается и резервируется уникальный MAC-адрес, что обеспечивает отсутствие коллизий MAC-адресов. Для этих целей используются ресурсы: VirtualMachineMACAddress (vmmac) и VirtualMachineMACAddressLease (vmmacl).
MAC-адрес генерируется случайным образом из пула разрешённых диапазонов.
- Диапазоны:
x2-xx-xx-xx-xx-xx,x6-xx-xx-xx-xx-xx,xA-xx-xx-xx-xx-xx,xE-xx-xx-xx-xx-xx. - Первые три октета (OUI) формируются на основе UUID кластера, последние три (NIC) — выбираются случайно из 16 миллионов возможных комбинаций.
Ресурс VirtualMachineMACAddressLease (vmmacl) - кластерный ресурс, который управляет арендой MAC-адресов из общего пула MAC-адресов.
Чтобы посмотреть список аренд MAC-адресов (vmmacl), используйте команду:
d8 k get vmmacl
Пример вывода:
NAME VIRTUALMACHINEMACADDRESS STATUS AGE
mac-5e-e6-19-22-0f-d8 {"name":"vm-01-fz9cr","namespace":"pr-sdn"} Bound 45s
mac-5e-e6-19-29-89-cf {"name":"vm-01-99qj6","namespace":"pr-sdn"} Bound 45s
mac-5e-e6-19-54-f9-be {"name":"vm-01-5jqxg","namespace":"pr-sdn"} Bound 45s
Ресурс VirtualMachineMACAddress (vmmac): проектный ресурс, который отвечает за резервирование арендованных MAC-адресов и их привязку к виртуальным машинам.
MAC-адреса виртуальной машине назначается автоматически на каждый дополнительный интерфейс из общего пула адресов и закрепляется за ней до её удаления.
Проверить назначенные MAC-адреса можно с помощью команды:
d8 k get vmmac
Пример вывода:
NAME ADDRESS STATUS VM AGE
vm-01-5jqxg 5e:e6:19:54:f9:be Attached vm-01 5m42s
vm-01-99qj6 5e:e6:19:29:89:cf Attached vm-01 5m42s
vm-01-fz9cr 5e:e6:19:22:0f:d8 Attached vm-01 5m42s
При удалении сети из конфигурации ВМ:
- MAC-адрес интерфейса освобождается.
- Автоматически удаляются связанные ресурсы
VirtualMachineMACAddressиVirtualMachineMACAddressLease.